|
|
 pandas练习文档(1).xlsx pandas练习文档(1).xlsx
416.6K
· 百度网盘
1、索引简介
索引(index)是数据处理中非常重要的工具。索引主要用来:
1)标记数据;2)快速检索数据;
Pandas中的索引,有两种:1)index(行索引);2)columns(列索引);
数据准备
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
print(df)

2、设置索引的常用方法
2.1 读取数据时设置索引
import pandas as pd
#读取数据,同时,使用index_col选取第一列作为索引列。
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3,index_col=0)
print(df)

2.2 查看索引相关信息
2.2.1 df.index
import pandas as pd
#读取数据时,设置了index
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3,index_col=1)
print(df)
print('\n')
print(df.index)

2.3 设置索引列的名称
2.3.1 df.rename_axis()
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
print(df)
print('\n')
df = df.rename_axis('index_col')
print(df)

2.3.2 df.index.name
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
print(df)
print('\n')
df.index.name = 'index_col'
print(df)

2.3.3 df.index.names = []
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
#set_index()是设置索引列,reset_index()可以将索引列变成数据列。
df = df.set_index(keys=['id','name'],drop=True,append=True)
df_new = df.reset_index(level=1,drop=False)
print(df_new)
print('\n')
df_new.index.names = ['x','y']
print(df_new)

2.3.4 df.columns=values
import pandas as pd
#先设置多级别index
index = pd.MultiIndex.from_tuples([('girl','Lucy'),
('girl','Rose'),
('boy','Tom'),
('boy','Jack'),
],
names=['gender','name'])
#设置columns,一列一个元组,如果是多级别,在一个元组内。
columns = pd.MultiIndex.from_tuples([('math',),
('english',)])
#构造数据。
df = pd.DataFrame([
(99,78),
(87,32),
(23,89),
(28,81)
],
index=index,
columns=columns)
print(df)
df.columns=['数学','英语']
print('\n')
print(df)
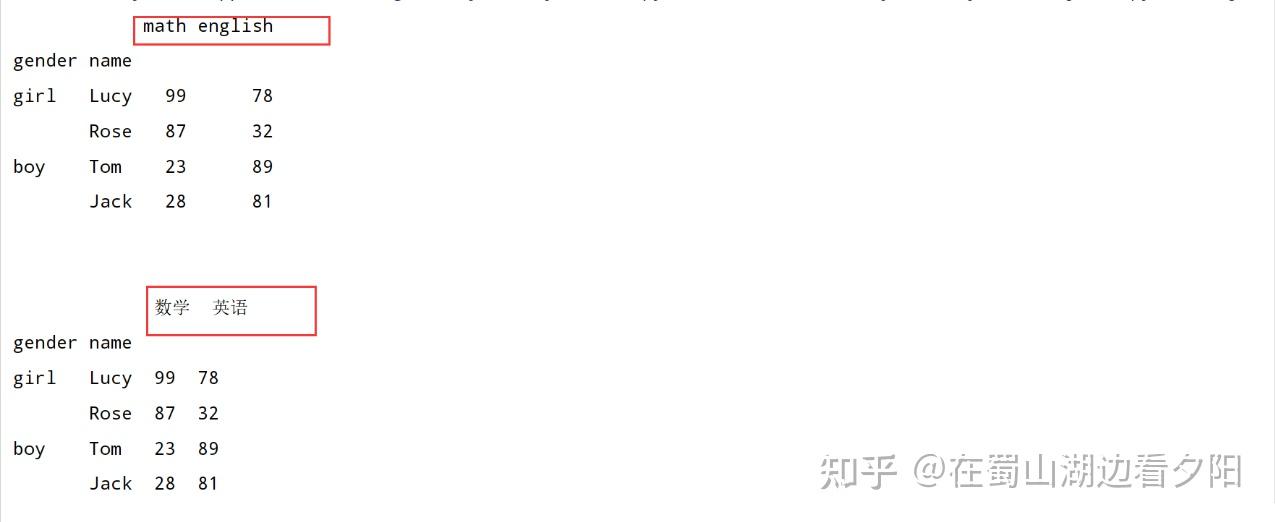
2.4 重置索引:df.index=values
使用赋值的方法。
【注:重置索引后,不会将原来的索引列作为新的一列保留。】
import pandas as pd
#读取数据,同时,使用index_col选取第一列作为索引列。
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3,index_col=0)
df.index = range(len(df))
print(df)

2.5 重置索引:df.reset_index()
2.5.1 df.reset_index()参数详情
reset_index(
level=None, #如果索引有多个层级,仅从索引中删除level指定的列。默认为删除所有的列。
drop=False, #重置索引后,是否将原来的索引列作为新的一列保留。默认为False,即保留。
col_level=0, #如果列有多个级别,确定将这一索引列插入到哪一个级别。默认情况为0,即插入到第一级别。
col_fill='' ,#确定如何命名其他级别。
inplace=False#是否要用新的DataFrame替换原来的DataFrame,一般默认为False。
)
2.5.2 修改索引,并保留原来的索引列为新的一列
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3,index_col=0)
#重置索引,会将原来的索引列,变成新的一列。
df_new = df.reset_index()
print(df,df_new,sep='\n')

2.5.3 删除索引:将索引的列的第二列,变成数据列的第二列
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
#先用set_index()增加几个索引
df = df.set_index(keys=['id','name'],drop=True,append=True)
print(df)

使用df.reset_index()将id列变成数据列
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
#set_index()是设置索引列,reset_index()可以将索引列变成数据列。
df = df.set_index(keys=['id','name'],drop=True,append=True)
df_new = df.reset_index(level=1,drop=False)
print(df,df_new,sep='\n')

2.5.4 多级别索引的处理
1)使用MultiIndex构造多级别索引
import pandas as pd
#先设置多级别index
index = pd.MultiIndex.from_tuples([('girl','Lucy'),
('girl','Rose'),
('boy','Tom'),
('boy','Jack'),
],
names=['gender','name'])
#设置columns,一列一个元组,如果是多级别,在一个元组内。
columns = pd.MultiIndex.from_tuples([('math',),
('english',)])
#构造数据。
df = pd.DataFrame([
(99,78),
(87,32),
(23,89),
(28,81)
],
index=index,
columns=columns)
print(df)

将索引"gender"当成数据列。
df = df.reset_index(level='gender')
print(df)

2.6 重置索引:df.set_index()
2.6.1 df.set_index()参数详解
set_index(
keys, #要设置索引的列名。
drop=True, #将设置索引的列删除,默认为True,即不保留。
append=False, #是否保留原索引。默认为False。
inplace=False, #是否在替换原来的DataFrame。默认为False。
verify_integrity=False#是否检查索引有无重复,默认为False。
)
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
#先用set_index()增加几个索引
df = df.set_index(keys=['id','name'],drop=False,append=True)
print(df)

2.7 重置索引:df.reindex()
2.7.1 df.reindex()参数详解
【注:这个参数对其中某些值如method,即使按照官网上的操作,还是报错。我也没弄特别清楚】
pandas.DataFrame.reindex — pandas 1.5.2 documentation
df.reindex(
keywords for axes, #列标签,行标签。即index=,columns等。
method=None, #默认为None。针对填入的数据是向前,向后,向左,还是向右。{None, 'backfill'/'bfill', 'pad'/'ffill', 'nearest'}
copy=True,
level=None, #多级别索引时使用。
fill_value=nan, #一般默认填入NaN。可以设置。
limit=None, #向前或向后填入的最大连续数。
tolerance=None2.7.2 基本用法
import pandas as pd
df = pd.DataFrame([
(99,78),
(87,32),
(23,89),
(28,81)
])
print(df)
print('\n')
#使用df.reindex()重新赋值索引。
df = df.reindex([0,'B',3,'D'])
print(df)

fill_value的使用
import pandas as pd
df = pd.DataFrame([
(99,78),
(87,32),
(23,89),
(28,81)
])
print(df)
print('\n')
#使用df.reindex()重新赋值索引。
df = df.reindex([0,'B',3,'D'],fill_value='--')
print(df)

修改columns
import pandas as pd
df = pd.DataFrame([
(99,78),
(87,32),
(23,89),
(28,81)
],columns=['math','english'])
print(df)
print('\n')
#使用df.reindex()重新赋值索引。
df = df.reindex(columns=['math','english','music'],fill_value='100')
#或者使用
print(df)
 |
|



 发表于 2023-1-16 07:31:24
发表于 2023-1-16 07:31:24