|
|
Reactor
初识Reactor
! ! Reactor讲解
Reactor:响应式编程,区别于一般:Client去询问Server是否有变化并拉取数据的模式,响应式编程是后台有数据变化时主动push给订阅者,也就是Publisher-Subscriber模型。
一、特点
- 可组合性,即可以协调多个异步任务。
- 提供丰富的操作符。
- 订阅之前不会产生任何的动作。(即只有订阅的时候才执行操作)
- 冷热响应
- 冷响应:对于每个订阅者,包括在数据源处,数据推送都会从头开始。例如,如果源包装了HTTP调用,则会为每个订阅发出一个新的HTTP请求。
- 热响应:并不是每个订阅者都可以从头开始接收数据。后面的订阅者会在订阅后接收已推送的信号。
- 异步非堵塞
- 流量控制(背压控制)
Publisher的数据推送的过于频繁,Subscriber处理数据的速度跟不上Publisher推送的速度。这时候就用到背压控制:Subscriber向Publisher发送信号来控制Publisher push数据的速度。
可以用reactive库中的WebClient来进行实现。
二、Operators
1、filter: 过滤
对Flux流中包含的元素进行过滤,只留下满足指定条件的元素。
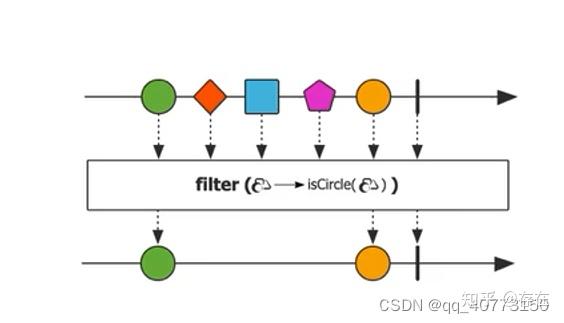
//只留下偶数元素
Flux.range(1,10).filter(i->i%2==0).subscribe(System.out::println);

2、map: 数据映射
把Flux的数据通过某些逻辑转换成另外的形式。
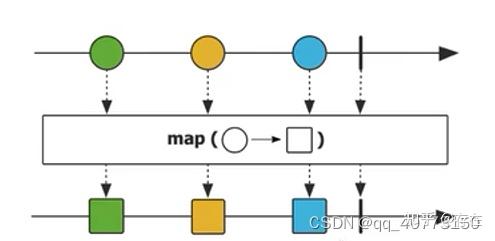
//结果为A B C
Flux.just("a","b","c").map(String::toUpperCase).subscribe(System.out::println);3、index: 编号
给Flux中的每个元素加上编号。
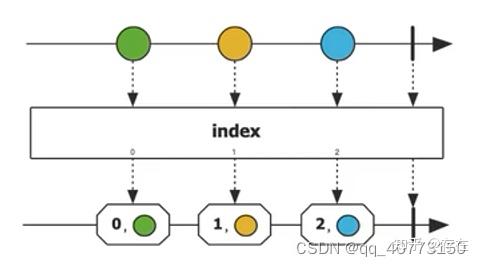
4、window: 分组
把当前流中的元素收集到另外的 Flux 序列中,也就是分组,分组结果为多个Flux序列。
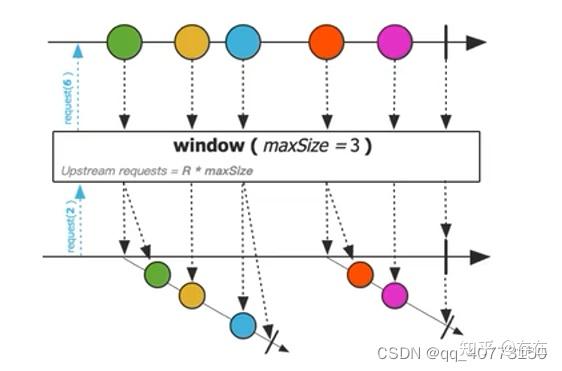
//把一个包含1-100的flux序列分组,20个为一组,每组为一个新的Flux序列
//这里window为一个包含5个Flux序列的Flux序列数组,其中每个Flux有20个元素
Flux<Flux<Integer>> window = Flux.range(1,100).window(20);
window.subscribe(System.out::println);

为什么输出的结果是UnicastProcessor?
其实,在调用window()方法的时候,其调用过程大致如下:
- 序列得到订阅,则开始首次发送元素,这时候会创建一个新的源序列UnicastProcessor。
- 当UnicastProcessor接受的元素数量到达20个时,执行对应的onComplete()方法。
- 那么当第21个元素发送的时候,又会创建一个新的源序列UnicastProcessor,并向下游传递,以此类推。
注意: window和buffer的区别
(首先有个前提,我们数据都是从上游往下游进行传输的)
- window是先创建一个UnicastProcessor序列,然后直接向下游传递。
- buffer是先收集满20个元素,再向下游进行传递。
5、buffer:分组
对一个Flux的元素进行分组,分组结果还是1个Flux序列。
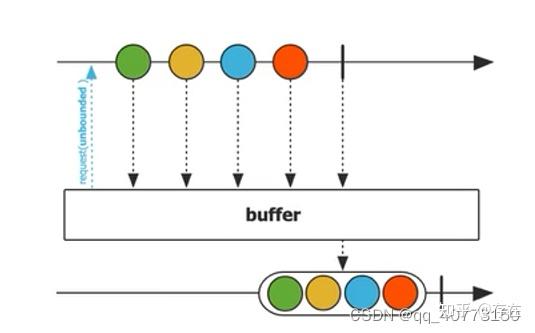
5.1 buffer:有一个参数,指定了每组所包含的元素的最大数量
//结果:输出5组数据,每一组数据包含20个元素
Flux.range(1,100).buffer(20).subscribe(System.out::println)

5.2 bufferUntil:参数表示每个集合中的元素要满足的条件。bufferUntil会一直收集,直到条件==true
//结果:输出5组数据,每一组包含2个元素
//只有当前元素为偶数的时候,才会停止当前元素的收集(当前组包含当前元素),接下来的元素另起组
Flux.range(1,10).bufferUntil(i->i%2==0).subscribe(System.out::println);
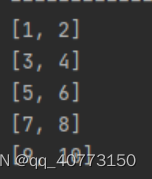
5.3 bufferTimeout:2个参数,分别制定了每组所包含的元素的最大数量、收集的时间间隔
5.4 bufferWhile:参数表示每个集合中的元素要满足的条件。bufferWhile则只有当条件==true时才会收集。一旦为false,会立即开始下一次收集。
//结果:输出5组数据,每组包含1个元素
//只有当前元素为偶数时,才进行元素收集
Flux.range(1,10).bufferWhile(i->i%2==0).subscribe(System.out::println);
6、take: 提取数据
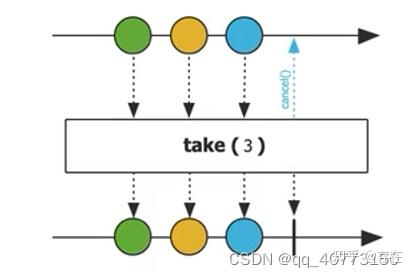
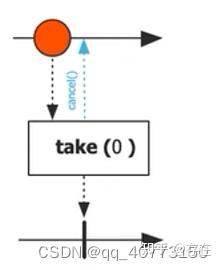
6.1 take
//取前三个元素
//结果为1 2 3
Flux.range(1,100).take(3).subscribe(System.out::println);6.2 takeLast
//取最后三个元素
//结果为98 99 100
Flux.range(1,100).takeLast(3).subscribe(System.out::println);6.3 takeWhile
//当条件为真时才进行提取
//结果为1 2
Flux.range(1,100).takeWhile(i->i<3).subscribe(System.out::println);6.4 takeUntil
//当条件为真时停止提取
//结果为1 2
Flux.range(1,100).takeWhile(i->i==3).subscribe(System.out::println);7、zipWith:元素合并
将两个Flux流中的元素按照一对一的方式进行合并
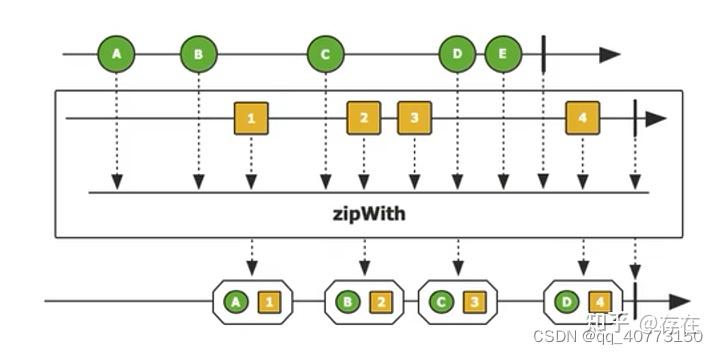
注意:
- 在合并时可以不做任何处理,由此得到的是一个元素类型为 Tuple2 的流。
- 若某个序列中的元素数量偏多或者偏少,那么多余的结果并不会输出。
// 结果:[a,c] [b,d]
Flux.just(&#34;a&#34;, &#34;b&#34;)
.zipWith(Flux.just(&#34;c&#34;, &#34;d&#34;,&#34;e&#34;,&#34;f&#34;))
.subscribe(System.out::println);
// 结果:a-c b-d
//第二个参数为逻辑处理流程
Flux.just(&#34;a&#34;, &#34;b&#34;)
.zipWith(Flux.just(&#34;c&#34;, &#34;d&#34;), (s1, s2) -> String.format(&#34;%s-%s&#34;, s1, s2))
.subscribe(System.out::println);

8、reduce:累加、累积
对流中包含的所有元素进行累积操作,得到一个包含计算结果的 Mono 序列
注意:
- 在操作时可以指定一个初始值。如果没有初始值,则序列的第一个元素作为初始值。
- 累积操作并不单单代表累加、累积的任意一种,而指的是对所有的元素做一个统一的操作,可能是累积、累加等一系列操作。
//1-100累加,结果为5050
Flux.range(1,100)
.reduce(Integer::sum)
.subscribe(System.out::println);
//1-100累加再加上100,结果为5150
Flux.range(1, 100)
.reduceWith(() -> 100, Integer::sum)
.subscribe(System.out::println);9、merge:流合并
把多个流合并成一个 Flux 序列
Flux.merge(
Flux.interval(Duration.ZERO, Duration.ofMillis(100)).take(9),
Flux.interval(Duration.ofMillis(50), Duration.ofMillis(100)).take(2),
Flux.interval(Duration.ofMillis(100), Duration.ofMillis(100)).take(3)
).subscribe((t) -> System.out.println(&#34;Flux.merge :&#34; + t + &#34;,线程:&#34; + Thread.currentThread().getName()));
// 让主线程睡眠2s,保证上面的输出能够完整
Thread.sleep(2000);
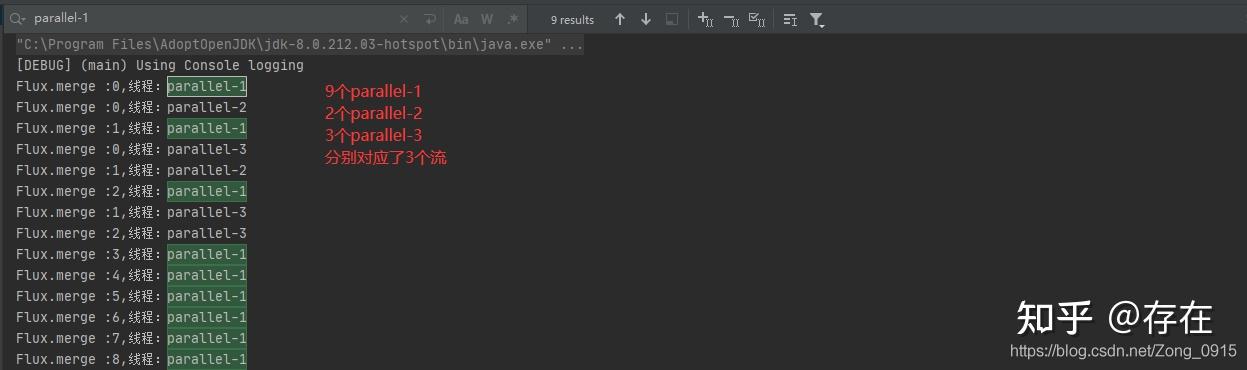
注意:
- merge() 会按照所有流中元素的实际产生顺序来合并,代码中定义了每个流中元素产生的时间间隔。
- merge()方法的兄弟方法:mergeSequential(),按照所有流被订阅的顺序,以流为单位进行合并。
- 代码中对Flux.interval()方法生成的流,采用了take()操作来制定获取的元素,若不采用,那么该流是一个无限序列。
10、interval:延迟
Flux.interval(xxx1,xxx2):时间类操作符,按照指定的参数来创建流。
- xxx1:第一次执行的延迟时间。
- xxx2:每隔多少秒发送一次事件,发送的内容是Long类型整数,从0开始。
11、flatMap:转换并合并结果
把流中的每个元素转换成一个流,再把所有流中的元素进行合并
Flux<String> stringFlux1 = Flux.just(&#34;a&#34;, &#34;b&#34;, &#34;c&#34;, &#34;d&#34;, &#34;e&#34;, &#34;f&#34;, &#34;g&#34;, &#34;h&#34;, &#34;i&#34;);
// [a,b],[c,d],[e,f],[g,h],
Flux<Flux<String>> stringFlux2 = stringFlux1.window(2);
stringFlux2.flatMap(flux1 -> flux1.map(String::toUpperCase)).subscribe(System.out::print);

12、concatMap:转换并合并结果
concatMap 操作同样是根据源中的每个元素来获取一个子源,再把所有子源进行合并。
Flux.just(5, 10)
// 将源中的每个元素来获取一个子源,那么这里的x指的是5或者10
// 然后以元素10为例:x=10,通过Flux.interval来生成序列,并取出10-3=7个元素
.concatMap(x -> Flux
//延迟x*10ms,之后每100ms开始生成从0开始的元素:0、1、2、3、4……
.interval(Duration.ofMillis(x * 10), Duration.ofMillis(100))
//将原本Flux流中的两个元素和interval生成的元素通过map合并
//形式为x:i
.map(i -> x + &#34;: &#34; + i)
//取最终流中的前x-3个元素
.take(x - 3))
.toStream()
.forEach(System.out::println);

注意: concatMap和flatMap有什么不同?
- 顺序:concatMap 操作会根据初始源中的元素顺序依次将获取到的子源进行合并。而flatMap是不会的。
- 订阅:concatMap 操作对所获取到的子源的订阅是动态进行的,而flatMap则是在合并开始之前就订阅了由父源下发的所有子源。(?不懂)
13、groupBy:分组
通过一个策略 key 将一个 Flux分割为多个组
Flux.just(1, 2, 3, 4, 5, 6, 7, 8, 9)
//分组,偶数为一组,奇数为一组。key分别为even和odd
.groupBy(i -> i % 2 == 0 ? &#34;even&#34; : &#34;odd&#34;)
//合并两个Flux流
.concatMap(i -> i
//defaultIfEmpty:如果没有任何数据完成此序列,则提供默认的唯一值
.defaultIfEmpty(-1)
//强制转换为String
.map(String::valueOf)
//不确定,应该是以i的key为每个i的前缀,这里i表示两个Flux流
.startWith(i.key())
)
.subscribe(System.out::println);

注意:
- 几个组之间的元素不会存在交集,也就是一个元素只属于其中1个组。
- 组永远不会为空,因为如果进行分组的时候发现没有对应的组,则进行创建操作。
14、defaultIfEmpty:分配默认值
如果没有任何数据完成此序列,则提供默认的唯一值

三、流式编程Example
消息驱动模式:subcribe()之前的代码描述应该发生什么,但是都尚未发生,直到有人subscribe(代码最后一行subcribe()),才会进行处理的流程(每个.之后都是一步流程) 。也就是订阅之前不会产生任何的动作。



当produces= MediaType.APPLICATION_STREAM_JSON_VALUE时,标注了stream,那么就表述在Publisher和Subcriber之间建立了一个长链接
四、Reactor Publisher
https://skyao.io/learning-reactor/docs/concept/flux/flux.html
https://segmentfault.com/a/1190000024499748
Publisher<T>是一个可以提供0-N个序列元素的提供者,并根据其订阅者Subscriber<? super T>的需求推送元素。一个Publisher<T>可以支持多个订阅者,并可以根据订阅者的逻辑进行推送序列元素。
下面这个Excel计算就能说明一些Publisher<T>的特点。
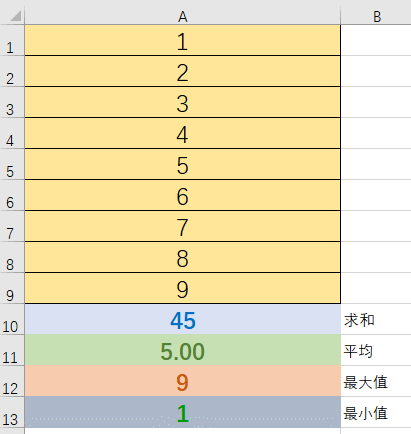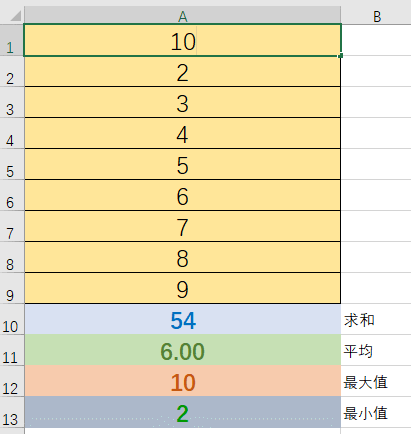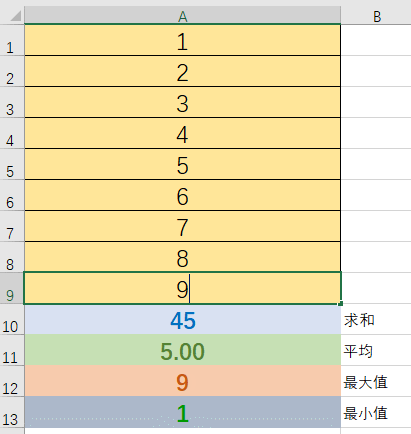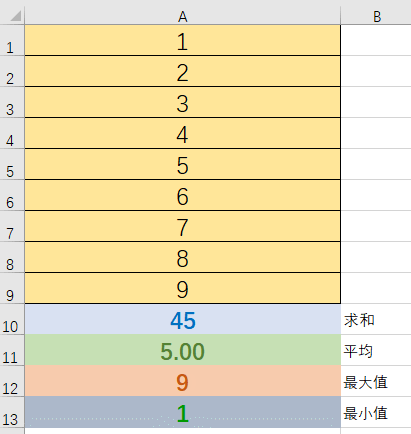
A1-A9就可以看做Publisher<T>及其提供的元素序列。A10-A13可以看作订阅者Subscriber。假如说我们没有A10-A13,那么A1-A9就没有实际意义,它们并不产生计算。这也是响应式的一个重要特点:当没有订阅时发布者什么也不做。
而Flux和Mono都是Publisher<T>在Reactor 3实现。
4.1 Flux(一串数据的抽象)
Flux作为Publisher,产生0-N个数据对象 ==> 数据对象交给operator()处理器进行处理 ==> 生成另外的数据对象。
Flux 是一个发出(emit)0-N个元素组成的异步序列的Publisher<T>.
在响应流规范中存在三种给下游消费者调用的方法 onNext, onComplete, 和onError。
- 正常的包含元素的消息:onNext()
- 序列结束的消息:onComplete()
- 序列出错的消息:onError()
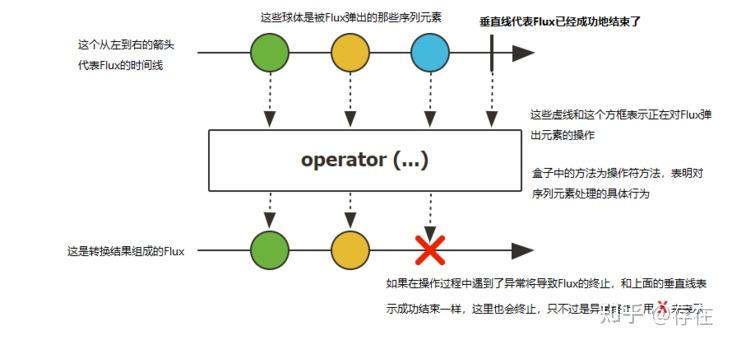
- Flux序列中可以有n个元素,每个元素都会经过operator操作进行数据的转换然后输出。
- 如果由于某些原因发生了错误,那么会终止该序列。
4.1.1 创建Flux
(1) generate
generate()方法的结构:
generate(
// 用于初始化值
Callable<S> stateSupplier,
// 生成器,也就是逻辑处理的函数
BiFunction<S, SynchronousSink<T>, S> generator,
// consumer,用于在序列终止的时候调用执行,比如关闭数据源
Consumer<? super S> stateConsumer
);
/**
简单来看,该方法的调用就是三步走:
初始化。
逻辑处理。
终止处理(fiinally)
**/ 简单例子:
Flux.generate(t->{
t.next(1);
t.complete();
}).subscribe(System.out::println);
//创建一个Flux,有1个元素
//注意generate中next只能调用1次复杂例子:
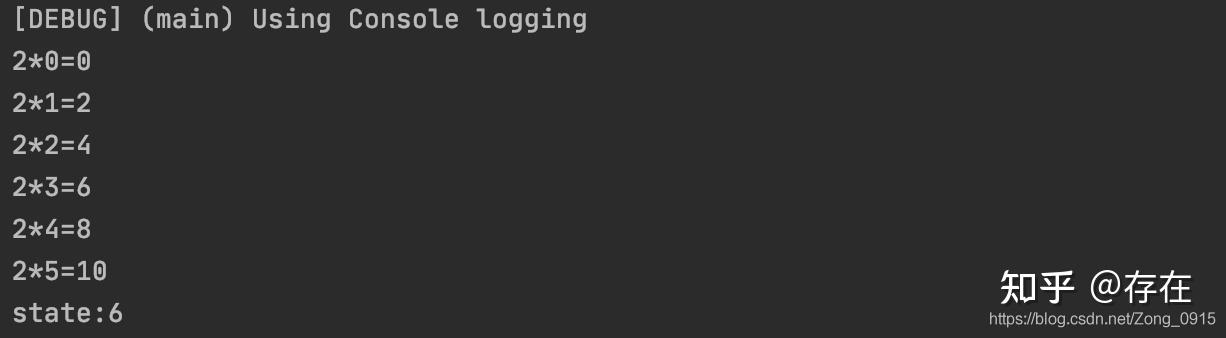
public void testGenerate() {
Flux.generate(
// 1.生成一个对象,用来作为状态,即初始化操作。
AtomicInteger::new,
// 2.逻辑处理
(state, sink) -> {
// 改变状态值
int i = state.getAndIncrement();
sink.next(&#34;2*&#34; + i + &#34;=&#34; + 2 * i);
if (i == 5) {
// sink事件结束。
sink.complete();
}
return state;
},
// 3.序列终止时,输出状态值。
(state) -> System.out.println(&#34;state:&#34; + state)
).subscribe(System.out::println);
}

(2) create
create()方法的结构:
// 一个参数时,第一个参数为逻辑处理函数/lambda表达式,第二个参数不写时默认为Buffer(背压策略之一)
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter) {
return create(emitter, OverflowStrategy.BUFFER);
}
//两个参数时,第一个参数为逻辑处理函数/lambda表达式,第二个参数为背压策略
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter, OverflowStrategy backpressure) {
return onAssembly((Flux)(new FluxCreate(emitter, backpressure, CreateMode.PUSH_PULL)));
}
简单例子
Flux.create((t)->{
t.next(1);
t.next(2);
t.complete();
}).subscribe(System.out::println);
//创建一个Flux,有多个元素,也就是可以多次发射复杂例子
private Flux<EventSource.Event> createFlux(FluxSink.OverflowStrategy strategy) {
// 事件源注册了一个监听器,负责监听新事件的创建以及事件源的停止
return Flux.create(sink -> eventSource.register(new MyListener() {
@Override
public void newEvent(EventSource.Event event) {
System.out.println(&#34;上游------>数据源创建了新事件:&#34; + event.getMsg());
sink.next(event);
}
@Override
public void eventSourceStopped() {
sink.complete();
}
}), strategy); // 别忘了这里还有个背压策略的参数
}Create() 方法跟Generate() 比较来看,有这么几个不同:
1、Create() 可以同步、也可以异步。而Generate() 是同步的。
//自定义一个事件源类EventSource:
public class EventSource {
private List<MyListener> listeners;
public EventSource() {
this.listeners = new ArrayList<>();
}
public void register(MyListener listener){
listeners.add(listener);
}
public void newEvent(Event event){
for (MyListener listener : listeners) {
listener.newEvent(event);
}
}
public void eventStopped(){
for (MyListener listener : listeners) {
listener.eventSourceStopped();
}
}
@Data
@AllArgsConstructor
public static class Event{
private Date time;
private String msg;
}
}
//定义一个监听器接口MyListener
public interface MyListener<T> {
// 监听新事件
void newEvent(EventSource.Event event);
// 监听事件源的终止
void eventSourceStopped();
}
//测试方法
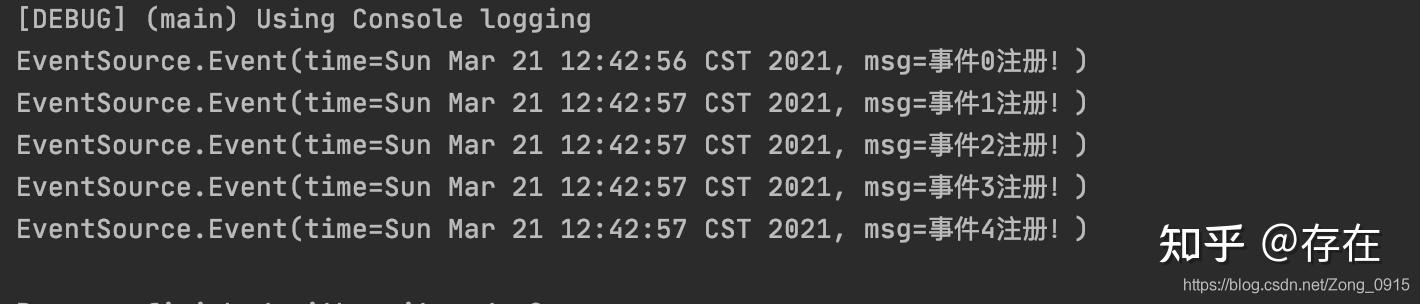
// 1.构建一个事件源
EventSource eventSource = new EventSource();
Flux.create(sink -> {
// 2.向事件源中添加一个监听器,负责监听事件的产生和事件源的停止。
// 相当于将事件转换成异步的事件流
eventSource.register(new MyListener() {
@Override
public void newEvent(EventSource.Event event) {
// 3.监听器收到事件回调的时候,会通过sink将事件发出
sink.next(event);
}
@Override
public void eventSourceStopped() {
// 4.监听器收到事件源停止的回调后,由sink发出完成信号,停止sink
sink.complete();
}
});
}).subscribe(System.out::println);
// 5.循环产生订阅
for (int i = 0; i < 5; i++) {
TimeUnit.MILLISECONDS.sleep(new Random().nextInt(1000));
eventSource.newEvent(new EventSource.Event(new Date(), &#34;事件&#34; + i + &#34;注册!&#34;));
}
// 6.停止事件源
eventSource.eventStopped();
2、Create() 可以每次发出多个元素,而Generate() 每次发出一个。
//create()
Flux.create(sink -> {
for (int i = 0; i < 5; i++) {
sink.next(i);
}
sink.complete();
}).subscribe(System.out::println);
//generate()
Flux.generate(t->{
t.next(1);
t.complete();
}).subscribe(System.out::println);3、Create() 不需要状态值。
4、Create() 可以在回调中触发多个事件。
5、Create() 是多线程的。
(3) push
Create有一个变体模式:push()方法,和create()方法不同的是,他是一个单线程的,即只有一个线程可以调用next(),complete()方法。
(4) just
Flux.just(&#34;1&#34;,&#34;2&#34;).subscribe(System.out::println);
//just(&#34;1&#34;,&#34;2&#34;)可以列举生成序列的所有元素(这里是1、2),
//just()创建出来的序列,在发布元素后(subscribe())会自动结束(5) from(通过Publisher创建一个Flux)
//Flux->Flux
Flux.from(Flux.just(&#34;just&#34;, &#34;just1&#34;, &#34;just2&#34;)).subscribe(System.out::println);
//Mono->Mono
Flux.from(Mono.just(&#34;just&#34;)).subscribe(System.out::println);(6) fromArray(创建发出数组的Flux)
// fromArray()从一个数组对象中创建一个Flux对象
Integer[] arr = new Integer[]{1, 2, 3};
Flux<Integer> f4 = Flux.fromArray(arr);(7) fromIterable、fromStream
// fromIterable()从一个Iterable对象中创建一个Flux对象
Flux<String> f2 = Flux.fromIterable(Arrays.asList(&#34;str1&#34;, &#34;str2&#34;, &#34;str3&#34;));
// fromStream()从一个Stream对象中创建一个Flux对象
ArrayList<Integer> numList = new ArrayList<>();
numList.add(1);
Flux<Integer> f3 = Flux.fromStream(numList.stream());(8) defer(推迟发送)
Flux.defer(()->Flux.range(1,10)).subscirbe(System.out::println);(9) range
Flux.range(1,10).subscirbe(System.out::println);
//range(int starter, int counter),创建包含从starter开始的counter个Integer对象的序列
//例如:range(1,10)创建序列,包含从1起始的10个数量的Integer对象
//Integer 类在对象中包装了一个基本类型 int 的值。该类提供了多个方法:能在 int 类型和 String 类型之间互相转换,还提供了处理 int 类型时非常有用的其他一些常量和方法(10) interval(Duration period )、interval(Duration delay, Duration period)
创建一个包含了从0开始递增的Long对象的序列。其中包含的元素按照指定的间隔来发布。除了间隔时间之外,还可以指定起始元素发布之前的延迟时间
Flux.interval(Duration.of(10, ChronoUnit.SECONDS)).subscribe(System.out::println);
Flux.just(2, 4)
.flatMap(x -> Flux.interval(Duration.ofMillis(1000)).take(x))
.toStream()
.forEach(System.out::println);
//流中的元素被转换成每隔 1000毫秒产生的数量不同的流,再进行合并https://www.jianshu.com/p/8d80dcb4e7e0—>如何使用flatMap()
(11) intervalMillis(long period)、intervalMillis(long delay, long period)
与interval()方法相同,但该方法通过毫秒数来指定时间间隔和延迟时间
Flux.intervalMillis(1000).subscirbe(System.out::println);(12) empty()、never()、error()
// 创建一个不包含任何元素,只发布结束消息的序列。
// 并且这种方式不会进行后续传递,需要switchIfEmpty()方法来进行处理。
// 因为响应式编程中,流的处理是基于元素的,而empty()是没有元素的!
Flux<Object> empty = Flux.empty();
// 创建一个只包含错误消息的序列,里面的参数类型是Throwable
Flux<Object> error = Flux.error(new Exception(&#34;error!&#34;));
// 创建一个不包含任何消息通知的序列,注意区别empty(),empty还是会发布结束消息的。
Flux<Object> never = Flux.never();
4.1.2 订阅Flux流: subscribe()
//subscribe():订阅Flux序列,只有进行订阅后才回触发数据流,不订阅就什么都不会发生
Flux<Integer> integerFlux = Flux.just(1, 2, 3, 4);
integerFlux.subscribe(System.out::println);// lambda表达式
Flux<String> stringFlux = Flux.just(&#34;hello&#34;, &#34;world&#34;);
stringFlux.subscribe(System.out::println); (1) 完整参数subcribe()方法
/**
* consumer:即如何处理数据元素,比如可以打印输出print。
* errorConsumer:若发生错误如何处理,即错误信号(同时终止序列)。
* completeConsumer:即完成信号(同时终止序列)。
* subscriptionConsumer:订阅发生时候的处理逻辑
*/
public final Disposable subscribe(@Nullable Consumer<? super T> consumer,
@Nullable Consumer<? super Throwable> errorConsumer,
@Nullable Runnable completeConsumer,
@Nullable Consumer<? super Subscription> subscriptionConsumer)
{
return (Disposable)this.subscribeWith(new LambdaSubscriber(consumer, errorConsumer, completeConsumer, subscriptionConsumer));
}例如:
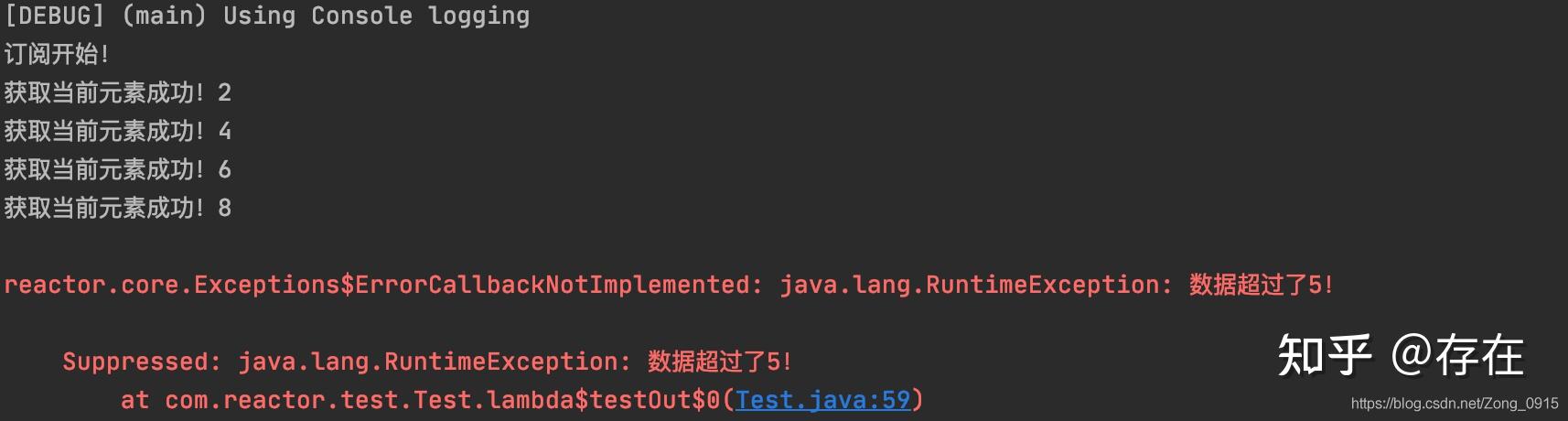
public class MySubscriber extends BaseSubscriber {
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println(&#34;订阅开始!&#34;);
// 订阅时首先向上游请求1个元素
request(1);
}
@Override
protected void hookOnNext(Object value) {
System.out.println(&#34;获取当前元素成功!&#34; + value);
// 每次处理完后再去请求1个元素
request(1);
}
}
public void testOut() {
// 1.创建一个序列
Flux<Integer> flux = Flux.range(1, 6)
.map(i -> {
if (i <= 4) {
return i * 2;
}
throw new RuntimeException(&#34;数据超过了5!&#34;);
});
// 2.订阅
MySubscriber ss = new MySubscriber();
flux.subscribe(System.out::println,
error -> System.out.println(&#34;Error:&#34; + error),
() -> System.out.println(&#34;Complete!&#34;),
s -> ss.request(2));
flux.subscribe(ss);
}
(2) Note:
- subscribe()方法的第四个参数只能接收一个自定义的Subscriber,需要重写BaseSubscriber。
- BaseSubscriber是一个抽象类,定义了多种用于处理不同信号的hook方法。
- 至少要重写hookOnSubscribe()方法和hookOnNext()方法。
- 若存在第四个参数,那么在对应的自定义订阅类中,对应重写的方法代替对应位置的lambda表达式。 比如我重写了onNext()方法,替换了原有lambda表达式中单纯的输出结果(加了几个中文字)。那么再简单点,说白了,BaseSubscriber是Lambda的替代品。
4.2 Mono(1\0个数据的抽象)
Mono作为Publisher,产生0-1个数据对象 ==> 数据对象交给operator()处理器进行处理 ==> 生成另外的数据对象
Mono 是一个发出(emit)0-1个元素的Publisher<T>,可以被onComplete信号或者onError信号所终止。
Flux 和 Mono 之间可以进行转换,例如:
- 对一个 Flux 序列进行计数操作,得到的结果是一个 Mono对象
- 把两个 Mono 序列合并在一起,得到的是一个 Flux 对象。
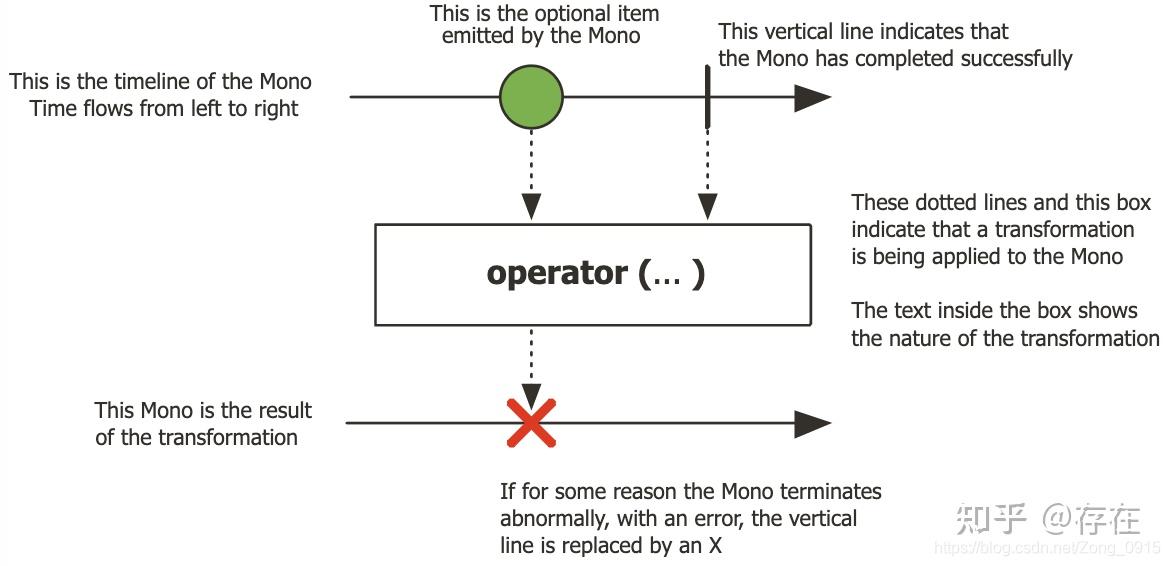
- 最多发出一项元素,并且以成功信号或者失败信号为终止信号。
//创建MONO
Mono.just(&#34;test hjf&#34;).subscribe(System.out::println);
Mono.empty().subscribe(System.out::println);
Mono.error(new Throwable()).subscribe(System.out::println);
Mono.never().subscribe(System.out::println);
//fromCallable()、fromCompletionStage()、fromFuture()、fromRunnable()和 fromSupplier():分别从 Callable、CompletionStage、CompletableFuture、Runnable 和 Supplier 中创建 Mono。
Mono.fromSupplier(() -> &#34;Hello&#34;).subscribe(System.out::println);
//justOrEmpty(Optional<? extends T> data)和 justOrEmpty(T data):从一个 Optional 对象或可能为 null 的对象中创建 Mono。只有 Optional 对象中包含值或对象不为 null 时,Mono 序列才产生对应的元素。
Mono.justOrEmpty(Optional.of(&#34;Hello&#34;)).subscribe(System.out::println);
//delay(Duration duration)和 delayMillis(long duration):创建一个 Mono 序列,在指定的延迟时间之后,产生数字 0 作为唯一值。
Mono.delay(Duration.ofSeconds(10)).subscribe(System.out::println);
//ignoreElements(Publisher<T> source):创建一个 Mono 序列,忽略作为源的 Publisher 中的所有元素,只产生结束消息。
Mono.ignoreElements(null).subscribe(System.out::println);
//还可以通过 create()方法来使用 MonoSink 来创建 Mono。
Mono.create(sink -> sink.success(&#34;Hello&#34;)).subscribe(System.out::println);五、Lambda表达式
六、背压
两种支持异步的生成Flux的方法create()和push(),支持背压操作,两个方法的第二个参数用于声明背压策略。
// 一个参数时,第一个参数为逻辑处理函数/lambda表达式,第二个参数不写时默认为Buffer(背压策略之一)
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter) {
return create(emitter, OverflowStrategy.BUFFER);
}
//两个参数时,第一个参数为逻辑处理函数/lambda表达式,第二个参数为背压策略
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter, OverflowStrategy backpressure) {
return onAssembly((Flux)(new FluxCreate(emitter, backpressure, CreateMode.PUSH_PULL)));
}6.1 背压策略
public static enum OverflowStrategy {
IGNORE,
//忽略下游的背压请求,上游push消息过快时会直接报错:IllegalStateException
ERROR,
//上游push消息过快时会直接报错:IllegalStateException
DROP,
//下游直接丢弃处理不了的event
LATEST,
//让下游只从上游获取最新event
BUFFER;
//(默认值)以在下游无法跟上时缓冲所有信号。(这会实现无限缓冲,并可能导致OutOfMemoryError)
private OverflowStrategy() {
}
}6.2 request()
request()方法用于限制下游向上游的请求个数,避免下游压力过大
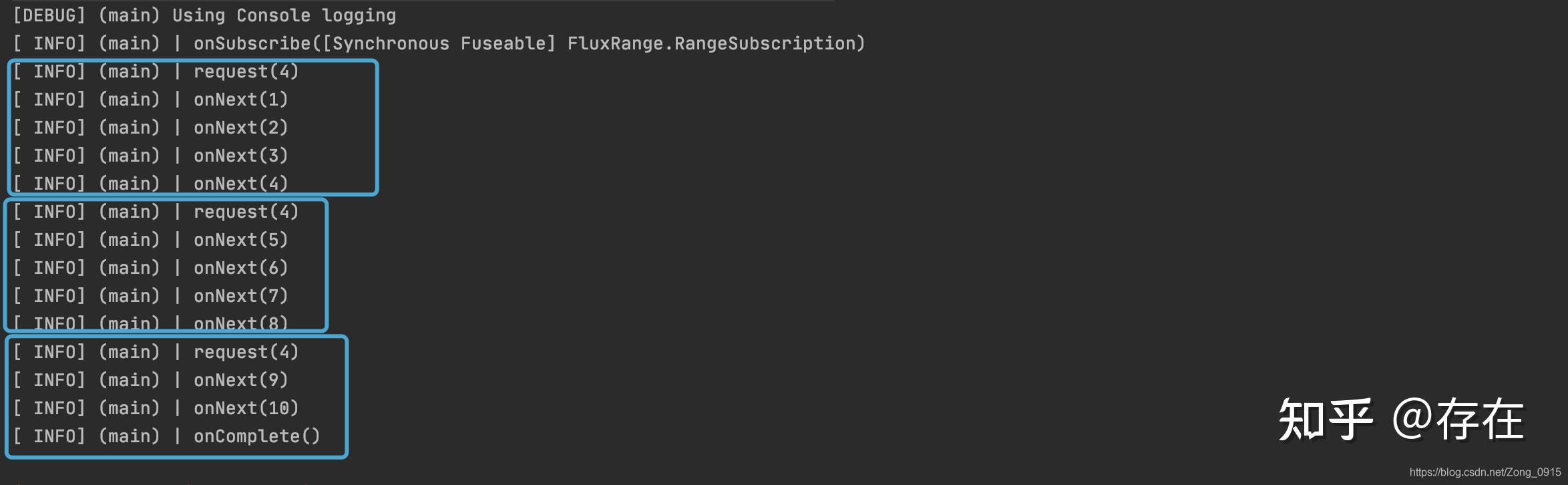
@Test
public void () {
Flux<Integer> flux = Flux.range(1, 10).log();
flux.subscribe(new BaseSubscriber<Integer>() {
private int count = 0;
private final int requestCount = 4;
@Override
protected void hookOnSubscribe(Subscription subscription) {
//订阅时,每次只让上游发送requestCount个请求
request(requestCount);
}
@SneakyThrows
@Override
protected void hookOnNext(Integer value) {
count++;
// 通过count控制每次request 4个元素
//如果队列里已经有4个元素没处理,那么就睡眠1s
if (count == requestCount) {
Thread.sleep(1000);
request(requestCount);
count = 0;
}
}
});
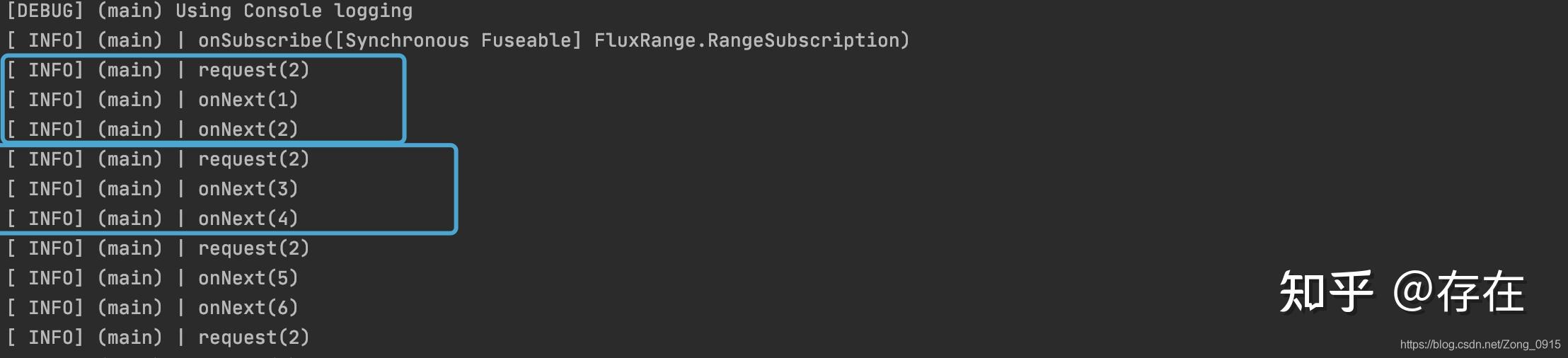
}结果(每个输出停顿1秒):
如果将变量requestCount改为2:结果会是2个2个输出
七、打包操作
用于调用外部公共方法。
transform()
//定义一个公共方法
//筛选出不以str开头的元素,并变成大写
Function <Flux<String>, Flux<String>> filterAndMap =
f->f.filter(color ->!color.startsWith(&#34;str&#34;)).map(String::toUpperCase);
//定义Flux序列
Flux.fromIterable(Arrays.asList(&#34;blue&#34;, &#34;green&#34;, &#34;orange&#34;, &#34;purple&#34;, &#34;yellow&#34;, &#34;str1&#34;, &#34;str2&#34;))
//调用外部函数
.transform(filterAndMap)
.subscribe(System.out::println);

compose()
//定义一个公共方法
AtomicInteger i = new AtomicInteger();
Function <Flux<String>,Flux<String>> function = f ->{
//第1个线程就抛去“str1”,并转换成大写字母
if(i.incrementAndGet()==1){
return f.filter(color -> !color.equals(&#34;str1&#34;)).map(String::toUpperCase);
}
//不是第1个线程就抛去“str2”,并转换成大写字母
return f.filter(color->!color.equals(&#34;str2&#34;)).map(String::toUpperCase);
}
//定义Flux序列
Flux<String> flux =
Flux.fromIterable(Arrays.asList(&#34;str1&#34;, &#34;str2&#34;, &#34;str3&#34;, &#34;str4&#34;))
// 调用外部定义好的function
.compose(function);
//第1个线程
flux.subscribe(d -> System.out.println(&#34;订阅者1:获得数据&#34; + d));
System.out.println(&#34;==============================================&#34;);
//第2个线程
flux.subscribe(d -> System.out.println(&#34;订阅者2:获得数据&#34; + d));

如果将compose()改为transform(),结果如下:

结论如下:
- compose()中打包的函数可以是有状态的,本案例中对应我们的AtomicInteger对象。
- transform()打包的函数是无状态的。
AtomicInteger
在Java语言中,++i和i++操作并不是线程安全的。而AtomicInteger是线程安全的,即使不使用synchronized关键字也能保证其是线程安全的,主要用于多线程间共享计数。
比如多个线程从列表中依次读取数据,使用AtomicInteger来计数,每次取第AtomicInteger个。而且由于AtomicInteger由硬件提供原子操作指令实现,在非激烈竞争的情况下,开销更小,速度更快。
AtomicInteger atomicInteger = new AtomicInteger();
//将原先的值进行了一个加1,但是返回的加1之前的值
atomicInteger.getAndIncrement()
//将原先的值进行了一个加1,返回的加1之后的值
atomicInteger.incrementAndGet()如果多线程想要借助AtomicInteger共享计数,需要在主线程(main)中创建并初始化AtomicInteger对象,再通过构造函数的引用传递才能实现多线程共享计数
public class TestThread extends Thread implements Runnable {
public static void main(String[] args) {
//使用此种方式,运行结果顺序递增,但是两个线程分别计数
//两个线程分别新建了一个AtomicInterge实例对象,所以不会共享计数
TestThread thread1 = new TestThread();
TestThread thread2 = new TestThread();
thread1.start();
thread2.start();
//使用此种方式,运行结果不一定顺序递增,但是统一计数
AtomicInteger testAtomicInteger = new AtomicInteger(0);
//两个线程使用同一个AtomicInterge实例对象,所以会共享计数
TestThread thread1 = new TestThread(testAtomicInteger);
TestThread thread2 = new TestThread(testAtomicInteger);
thread1.start();
thread2.start();
}
public TestThread() {
// 构造函数,每次使用构造函数都会初始化一个AtomicInteger=0
counterAtomicInteger = new AtomicInteger(0);
}
public TestThread(AtomicInteger counterAtomicInteger) {
// 构造函数,每次使用构造函数都会初始化一个作为参数传入的AtomicInteger
this.counterAtomicInteger = counterAtomicInteger;
}
}八、Schedule定时器
很多情况下,我们的publisher是需要定时去调用一些方法,来产生元素的。Reactor提供了一个新的Schedule类来负责定时任务的生成和管理。
Schedule是一个接口,定义了一些定时器中必须要实现的方法:
立即执行的:
Disposable schedule(Runnable task);延时执行的:
default Disposable schedule(Runnable task, long delay, TimeUnit unit)定期执行的:
default Disposable schedulePeriodically(Runnable task, long initialDelay, long period, TimeUnit unit)8.1 Schedulers调度器
Schedule有一个工具类叫做Schedulers,它提供了多个创建Scheduler的方法,它的本质就是对ExecutorService和ScheduledExecutorService进行封装,将其做为Supplier来创建Schedule。
Scheduler提供的静态方法用于创建如下几种线程环境:
(1) 当前线程:Schedulers.immediate()
提交的Runnable将会立马在当前线程执行。
(2) 可重用的单线程:Schedulers.single()
使用同一个线程来执行所有的任务。当各个调用者调用这个方法的时候,都会重用同一个线程,直到这个Scheduler的状态被设定为disposed。
(3) 弹性线程池:Schedulers.elastic()
该方法是一种将阻塞处理放在一个单独的线程中执行的很好的方式,即可以拿来包装一个堵塞方法,将其变为异步。
1.当首次调用这个方法的时候,会创建一个新的线程池,而且这个线程池中闲置的线程可以被重用。 2.如果一个线程的闲置时间太长(默认60s),则会被销毁。
(4) 固定大小线程池:Schedulers.parallel()
创建固定个数的工作线程,个数和CPU的核数相关。
(5) Schedulers.fromExecutorService(ExecutorService)
从一个现有的线程池创建Scheduler。
(6) Schedulers.newXXX
Schedulers提供了很多new开头的方法,来创建各种各样的Scheduler。
//可以指定特定的Scheduler来产生元素
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle(&#34;test&#34;))8.2 注意事项
- 某些Reactor的操作已经是默认使用了特定类型的调度器。例如Flux.interval()创建的源,使用了Schedulers.parallel()等。
- 可以通过publishOn和subscribeOn来进行切换Scheduler的执行上下文。publishOn()切换的是元素消费操作执行时所在的线程。subscribeOn()切换的是源中元素生产操作执行时所在的线程。
九、publishOn() / subscribeOn()
Flux和Mono不会创建线程,只有当触发subscribe()操作时才会执行对应的方法。
而有些操作符,例如publishOn()和subscribeOn()方法,能够创建线程。publishOn和subscribeOn主要用来进行切换Scheduler的执行上下文。
9.1 publishOn():
publishOn() 会强制下一个Operator(或许是下一个的下一个…)运行于不同的线程上。也就相当于publishOn()后面的逻辑都执行在另外一个线程上了。
例1:
Flux.range(1, 2)
.map(i -> {
System.out.println(Thread.currentThread().getName());
return i;
})
.publishOn(Schedulers.single())
.map(i -> {
System.out.println(Thread.currentThread().getName());
return i;
})
.publishOn(Schedulers.newParallel(&#34;parallel&#34;, 4))
.map(i -> {
System.out.println(Thread.currentThread().getName());
return i;
})
.subscribe();

流程是:
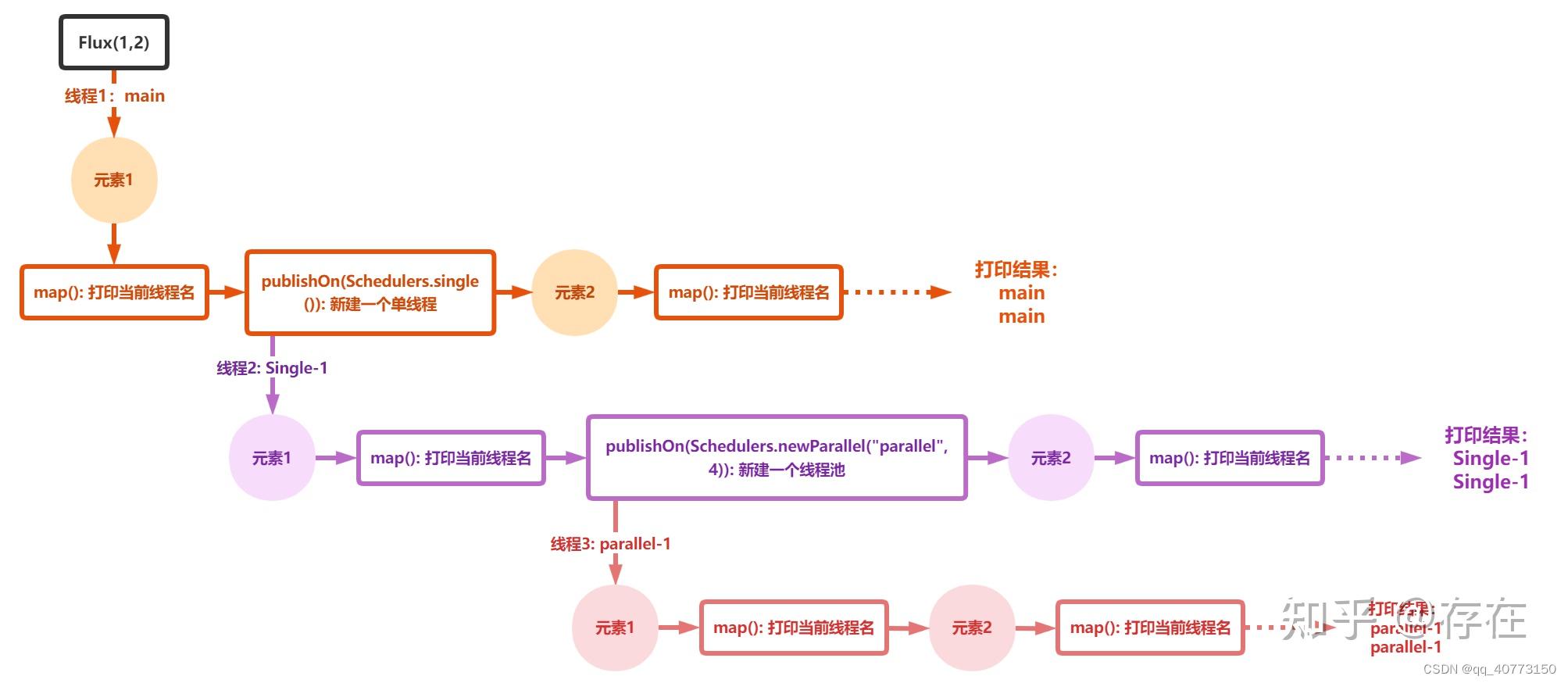
例2:
Scheduler s = Schedulers.newParallel(&#34;parallel-scheduler&#34;, 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i + &#34;:&#34;+ Thread.currentThread())
.publishOn(s)
.map(i -> &#34;value &#34; + i+&#34;:&#34;+ Thread.currentThread());
new Thread(() -> flux.subscribe(System.out::println),&#34;ThreadA&#34;).start();
System.out.println(Thread.currentThread());
Thread.sleep(5000);
- 上面创建了一个名字为parallel-scheduler的scheduler。
- 然后创建了一个Flux,Flux先做了一个map操作,然后切换执行上下文到parallel-scheduler线程,最后右执行了一次map操作。
- 最后,我们采用一个新的线程来进行subscribe的输出。
输出结果:
Thread[main,5,main]
value 11:Thread[ThreadA,5,main]:Thread[parallel-scheduler-1,5,main]
value 12:Thread[ThreadA,5,main]:Thread[parallel-scheduler-1,5,main]可以看到,主线程的名字是Thread。Subscriber线程的名字是ThreadA。
那么在publishOn之前,map使用的线程就是ThreadA。 而在publishOn之后,map使用的线程就切换到了parallel-scheduler线程池。
9.2 subscribeOn
subscribeOn是用来切换Subscriber的执行上下文,不管subscribeOn出现在调用链的哪个部分,最终都会应用到整个调用链上。
Scheduler s = Schedulers.newParallel(&#34;parallel-scheduler&#34;, 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i + &#34;:&#34; + Thread.currentThread())
.subscribeOn(s)
.map(i -> &#34;value &#34; + i + &#34;:&#34;+ Thread.currentThread());
new Thread(() -> flux.subscribe(System.out::println), &#34;ThreadA&#34;).start();
Thread.sleep(5000);例子同样使用了两个map,然后在两个map中使用了一个subscribeOn用来切换subscribe执行上下文。输出结果:
value 11:Thread[parallel-scheduler-1,5,main]:Thread[parallel-scheduler-1,5,main]
value 12:Thread[parallel-scheduler-1,5,main]:Thread[parallel-scheduler-1,5,main]可以看到,不管哪个map,都是用的是切换过的parallel-scheduler。
9.3 publishOn和subscribeOn的区别
- publishOn一般使用在订阅链的中间位置,并且从下游获取信号,影响调用位置起后续运算的执行位置。
- subscribeOn一般用于构造向后传播的订阅过程。并且无论放到什么位置,它始终会影响源发射的上下文。同时不会影响对publishOn的后续调用的行为。
- publishOn会强制让下一个运算符(或者下下个)运行于不同的线程上,subscribeOn会强制让上一个(或者上上个)运算符在不同的线程上执行。
十、Processor
https://blog.csdn.net/get_set/article/details/79799895
https://blog.csdn.net/Zong_0915/article/details/115048153
Processor既是一个Publisher也是一个Subscriber,是一个接口。 所以能够订阅一个Processor,也可以调用它们提供的方法来手动插入数据到序列,或终止序列。
其中的两个实现类:
- MonoProcessor
- FluxProcessor
而FluxProcessor又可以衍生出多种Processor,负责应对不同的场景使用:
- UnicastProcessor
- DirectProcessor
- EmitterProcessor
- ReplayProcessor
- TopicProcessor
- WorkQueueProcessor
十一、Context
https://blog.csdn.net/Zong_0915/article/details/115397437
https://blog.csdn.net/LCBUSHIHAHA/article/details/114837031#:~:text=Reactor%E4%B8%AD,ue%E7%9A%84%E5%BD%A2%E5%BC%8F%E5%AD%98%E5%82%A8%E3%80%82
11.1 Context用法:
- Mono.deferContextual(c-> c.get(key)):获得Context中指定Key对应的Value值。
- contextWrite(c -> c.put(key, value):往Context中塞入一个键值对。
- 简单用法的格式:Mono.deferContextual(c ->Mono.just(c.get(key)))
- contextWrite只对它上游的操作生效,对下游的操作不生效。
- 如果下游有多个contestWriter,上游会从邻近的contextWrite中读取上下文的信息。
11.2 Context用例
例子1
String key = &#34;message&#34;;
Mono<String> r = Mono.just(&#34;Hello&#34;)
.flatMap(s -> Mono
.deferContextual(ctx ->Mono.just(s + &#34; &#34; + ctx.get(key))))
.contextWrite(ctx -> ctx.put(key, &#34;World&#34;));
- 使用contextWrite()往Context中写入一个键值对,key:message,value:World。
- 在faltMap()中,通过Mono.deferContextual()获得一个Context对象,可以取出对应key的value值,并进行拼接。
- 结果是Hello World
结果说明:订阅是从下游流向上游的,contextWrite只对它上游的操作生效,对下游的操作不生效,在上边例子中也就是先调用了contextWrite(),然后才调用了Mono.flatMap()。
例子2:
String key = &#34;message&#34;;
Mono<String> r = Mono.just(&#34;Hello&#34;)
.flatMap(s -> Mono.deferContextual(ctx ->Mono.just(s + &#34; &#34; + ctx.get(key))))
.contextWrite(ctx -> ctx.put(key, &#34;Reactor&#34;))
.contextWrite(ctx -> ctx.put(key, &#34;World&#34;));
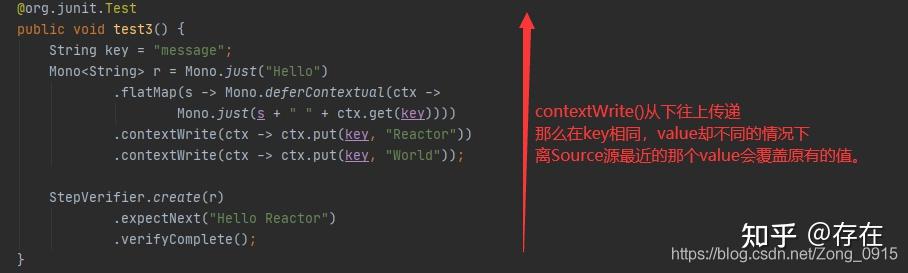
结果是Hello Reactor
例子3 ??:
String key = &#34;message&#34;;
Mono<String> r = Mono
.deferContextual(ctx -> Mono.just(&#34;Hello &#34; + ctx.get(key)))//3
.contextWrite(ctx -> ctx.put(key, &#34;Reactor&#34;))//2
.flatMap( s -> Mono.deferContextual(ctx ->Mono.just(s + &#34; &#34; + ctx.get(key))))//4
.contextWrite(ctx -> ctx.put(key, &#34;World&#34;));//1结果为Hello Reactor World
第一个需要获取上下文的deferContextual从邻近下游读取到Reactor,第二个flatMap邻近下游读取到的World。
例子4
String key = &#34;message&#34;;
Mono<String> r = Mono.just(&#34;Hello&#34;)
.flatMap( s -> Mono
.deferContextual(ctxView -> Mono.just(s + &#34; &#34; + ctxView.get(key)))
)
.flatMap( s -> Mono
.deferContextual(ctxView -> Mono.just(s + &#34; &#34; + ctxView.get(key)))
.contextWrite(ctx -> ctx.put(key, &#34;Reactor&#34;))
)
.contextWrite(ctx -> ctx.put(key, &#34;World&#34;)); 结果为Hello World Reactor
因为第一个contextWrite只影响内部的操作流。第二个contextWrite只会影响外部主操作流。
11.3 Spring WebFlux处理Context
思路:根据Reactor Context只对上游生效的特性,WebFlux只用在后置处理器中做contextWrite操作就可以了。遗憾的是在Spring WebFlux中没有HandlerInterceptorAdapter,但是可以使用过滤器WebFilter。
@Component
@Slf4j
public class AuthFilter implements WebFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return chain
.filter(exchange)
.contextWrite(ctx -> {
log.info(&#34;设置context内容。&#34;);
return ctx.put(&#34;token&#34;, &#34;xx&#34;);
//注意这里一定要return ctx.put
//put操作是产生一个新的context。如果是return ctx;会导致值没有设置进去
});
}}按照上面的处理方式,在我们业务开发中就能取到上下文的信息了。
@PostMapping(name = &#34;测试&#34;, value = &#34;/save&#34;)
public Mono<Test> save(@RequestBody Mono<Test> testMono) {
return testService
.add(testMono)
.log(&#34;&#34;, Level.INFO, true)
.flatMap(test -> {
return Mono
.contextWrite()
.map(ctx -> {
log.info(&#34;context:&#34; + ctx.get(&#34;token&#34;));
return test;
});
});
}如果想设置多个值可以像下面这样操作。
@Component
public class WebFluxFilter implements WebFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return chain
.filter(exchange)
.contextWrite(ctx -> {
return ctx.put(&#34;token&#34;, &#34;123123123123&#34;);
})
.contextWrite(ctx -> {
return ctx.put(&#34;liu&#34;, &#34;hah&#34;);
});
}
}十二、Reactor doOn系列函数
在Publisher使用subscribe()方法的时候,Subscriber触发回触发一系列的on方法,如onSubscribe();为了更好的监控以及观测异步序列的传递情况,设置了一系列的doOn方法,在触发onxxx方法的时候作为其副作\附加行为,用于监控行为的运行情况。
12.1 官网doOn方法解释
- Without modifying the final sequence, I want to:
- get notified of / execute additional behavior (sometimes referred to as &#34;side-effects&#34;) on:
(也就是在不改变Flux或Mono的情况下,以下情况发生时想被通知/想执行额外的行为)
- emissions: doOnNext (Flux|Mono)
- completion: Flux#doOnComplete, Mono#doOnSuccess (includes the result, if any)
- error termination: doOnError (Flux|Mono)
- cancellation: doOnCancel (Flux|Mono)
- &#34;start&#34; of the sequence: doFirst (Flux|Mono)
- this is tied to Publisher#subscribe(Subscriber)
- post-subscription : doOnSubscribe (Flux|Mono)
- Subscription acknowledgment after subscribe
- this is tied to Subscriber#onSubscribe(Subscription)
- request: doOnRequest (Flux|Mono)
- completion or error: doOnTerminate (Flux|Mono)
- but after it has been propagated downstream: doAfterTerminate (Flux|Mono)
- any type of signal, represented as a Signal: doOnEach (Flux|Mono)
- any terminating condition (complete, error, cancel): doFinally (Flux|Mono)
- log what happens internally: log (Flux|Mono)
- I want to know of all events:
- each represented as Signal object:
- in a callback outside the sequence: doOnEach (Flux|Mono)
- instead of the original onNext emissions: materialize (Flux|Mono)
- …and get back to the onNexts: dematerialize (Flux|Mono)
- as a line in a log: log (Flux|Mono)
12.1 常见doOn方法
- doOnEach(): 对每一个元素对应的single对象进行监控
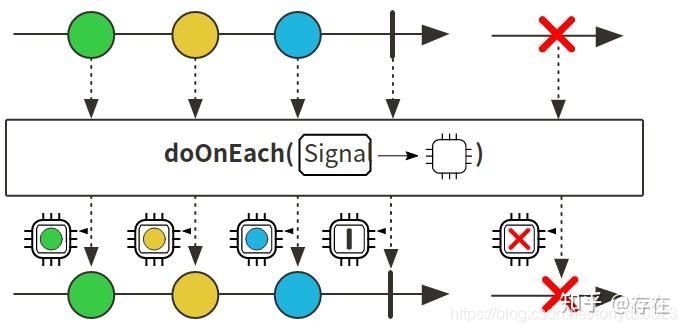
- doOnSubscribe(): 用以监控onSubscribe()方法的执行
/**
Add behavior (side-effect) triggered when the Flux is subscribed.
param onSubscribe the callback to call on onSubscribe
*/
public final Flux<T> doOnSubscribe(Consumer<? super Subscription> onSubscribe) {
Objects.requireNonNull(onSubscribe, &#34;onSubscribe&#34;);
return doOnSignal(this, onSubscribe, null, null, null, null, null, null);
}
- doOnRequest:对request行为监控产生副作用
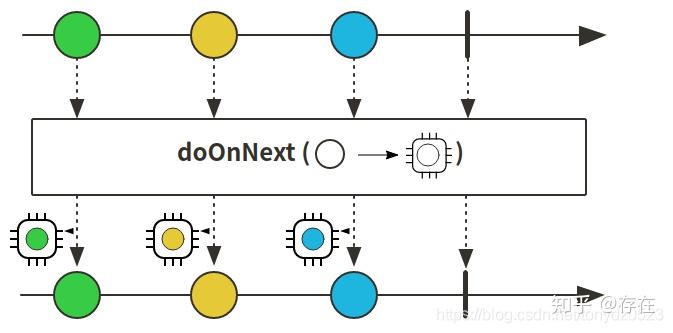
- doOnNext:onNext副作用
- doOnError:出现error时的副作用,用于监控报错,可以通过错误类型进行筛选
- doOnComplete:完成时触犯
- doOnCancel:取消时触发
- doOnTerminate:终止时触发,无论是成功还是出现异常
例子:
@Test
public void doOnWithMono () {
Mono.just(&#34;ffzs&#34;)
.map(String::toUpperCase)
.doOnSubscribe(subscription -> log.info(&#34;test do on subscribe&#34;))
.doOnRequest(longNumber -> log.info(&#34;test do on request&#34;))
.doOnNext(next -> log.info(&#34;test do on next1, value is {}&#34;, next))
.map(String::toLowerCase)
.doOnNext(next -> log.info(&#34;test do on next2, value is {}&#34;, next))
.doOnSuccess(success -> log.info(&#34;test do on success: {}&#34;, success))
.subscribe();
}
@Test
public void doOnWithFlux () {
Flux.range(1,10)
.map(i -> {
if (i == 3) throw new RuntimeException(&#34;fake a mistake&#34;);
else return String.valueOf(i);
})
.doOnError(error -> log.error(&#34;test do on error, error msg is: {}&#34;, error.getMessage()))
.doOnEach(info -> log.info(&#34;do on Each: {}&#34;, info.get()))
.doOnComplete(() -> log.info(&#34;test do on complete&#34;)) // 因为error没有完成时不触发
.doOnTerminate(() -> log.info(&#34;test do on terminate&#34;)) // 无论完成与否,只要终止就触发
.subscribe();
}
12.2 log()
reactor提供了一个很便利的监控方法:log()。在编写publisher的时候加上log(),在subscriber调用的时候会将触发的每一个behavior以日志的形式打印出来:
@Test
public void logTest () {
Flux.range(1,5)
.map(i -> {
if (i == 3) throw new RuntimeException(&#34;fake a mistake&#34;);
else return String.valueOf(i);
})
.onErrorContinue((e, val) -> log.error(&#34;error type is: {}, msg is : {}&#34;, e.getClass(), e.getMessage()))
.log()
.subscribe();
}效果如下,日志内容很详细,线程使用,onNext,request这些都会标明
 |
|



 发表于 2022-11-26 21:02:30
发表于 2022-11-26 21:02:30