|
|

没网的时候想看小说,咱就只能下载下来,那咱从《笔趣阁》上面扒一扒吧。 思路
- 咱先要知道小说的地址
- 创建一个下载本小说的文件夹
- 获取小说的所有章节
- 获取每章小说的内容
- 写入小说
代码
import requests
from bs4 import BeautifulSoup
import random
import os
# 小说地址
url = "http://www.ibiqu.org/book/38857/"
# 小说文件夹名称
folder = url.split('/')
# 列举头
user_agent = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1 ",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0 ",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50 ",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50 ",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3) ",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0) ",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12 ",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) ",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0) ",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0 ",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) ",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201 ",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201 ",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0) "
]
# 随机使用头
headers = {
'User-Agent': user_agent[random.randint(0, 16)]
}
# 创建文件夹
def mkdir():
mkdir_url = folder[len(folder)-2]
if os.path.exists(mkdir_url):
print(f'{mkdir_url}文件夹已存在')
else:
os.mkdir(mkdir_url)
print(f'{mkdir_url}已创建')
run()
# 获取章节地址
def run():
print('正在获取书籍章节')
res = requests.get(url, headers=headers, timeout=60)
res.encoding = 'gbk'
if res.status_code == 200:
soup = BeautifulSoup(res.text, 'lxml')
a = soup.find_all('a')
for i in a[38:len(a)-10]:
href_list = i.get('href').split('/')
href = href_list[len(href_list)-1]
title = i.text
cab(href, title)
# 获取每章的内容
def cab(href, title):
print(f'正在获取{title}内容')
res = requests.get(f'{url}{href}', headers=headers, timeout=60,)
res.encoding = 'gbk'
if res.status_code == 200:
soup = BeautifulSoup(res.text, 'lxml')
a = soup.find_all('div', id='content')
write(a[0].text, title)
# 写入小说
def write(content, title):
fs = open(f'./{folder[len(folder)-2]}/{title}.txt', 'a', encoding='utf-8')
fs.write(str(content))
fs.close()
print(f"已保存{title}")
mkdir()
结论
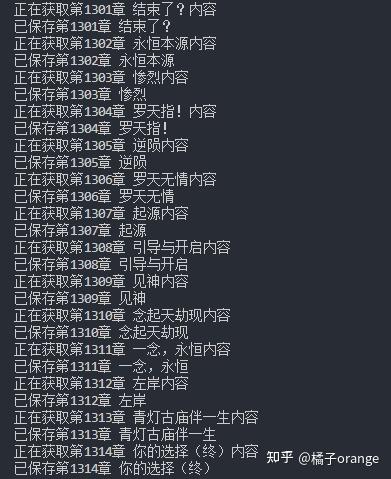
下载的过程
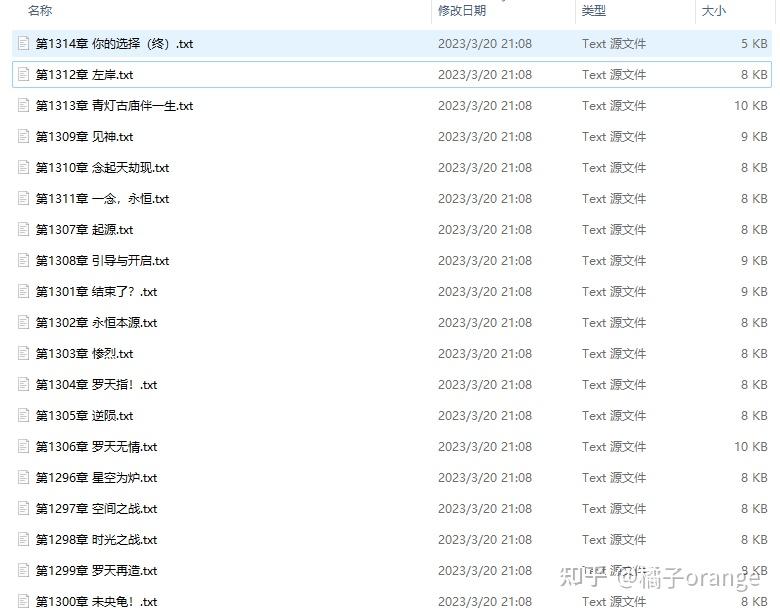
下载的结果 |
|



 发表于 2023-3-23 14:39:24
发表于 2023-3-23 14:39:24