|
|
 pandas练习文档(1).xlsx pandas练习文档(1).xlsx
416.6K
· 百度网盘
准备数据
import pandas as pd
#读取数据
#这一次读取的是sheet_name=1,1是索引序列。
df = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#查看数据
print(df)

1、增加行数据
1.1 df.loc[]:增加一行数据
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#df.loc[]
#df.loc[5]是确定这一行数据放的位置。这里我选择放到最后,当然也可以是df.loc[0]。后面的则是具体的数据。
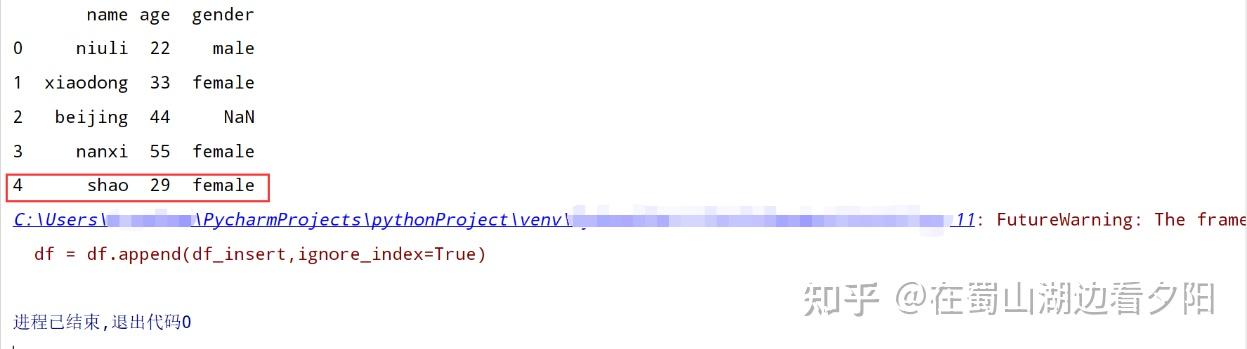
df.loc[5] = ['shao','29','female']
print(df)

1.2 df.append(data=list,dict,ignore_index=True/False):
两个参数,ignore_index(忽略索引),一般填True。
但是在目前的版本中会报FutureWarning。
FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.1.2.1 将list作为一行插入df
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#df.append()
insert_data = ['shao',29,'female']
#现将这个数据转化成df并用T转置。
#如果不转置,这里将是一列数据,无法与上面的df组合在一起的。
df_insert = pd.DataFrame(insert_data).T
# 设置相同columns。
df_insert.columns = ['name','age','gender']
# print(df_insert)
df = df.append(df_insert,ignore_index=False)
#如果这里是df = df.append(df_insert,ignore_index=True),则不需要重置索引一步了。
#重置索引
df.index=range(len(df))
print(df)

1.2.2 将dict作为一行插入df
这里补充一个知识点,单一dict转化成DataFrame的几种方法。
1)dict——>pd.DataFrame(insert_data,index=[0]),一定要注意这里的index=[0],如果不填会报错的。
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
insert_data = {'name':'shao','age': 29, 'gender':'female'}
#如果dict是这种格式,需要先将dict转化为DataFrame数据结构。
df_insert = pd.DataFrame(insert_data,index=[0])
# print(df_insert)
#添加行
df = df.append(df_insert,ignore_index=True)
print(df)

2)dict——>[dict]
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
insert_data = {'name':'shao','age': 29, 'gender':'female'}
#如果dict是这种格式,需要先将dict转化为DataFrame数据结构。
df_insert = pd.DataFrame([insert_data])
# print(df_insert)
#添加行
df = df.append(df_insert,ignore_index=True)
print(df)
3)pd.DataFrame.from_dict()
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
insert_data = {'name':'shao','age': 29, 'gender':'female'}
#如果dict是这种格式,需要先将dict转化为DataFrame数据结构。
#使用pd.DataFrame.from_dict()一定要用T转置
df_insert = pd.DataFrame.from_dict(insert_data,orient='index').T
# print(df_insert)
#添加行
df = df.append(df_insert,ignore_index=True)
print(df)
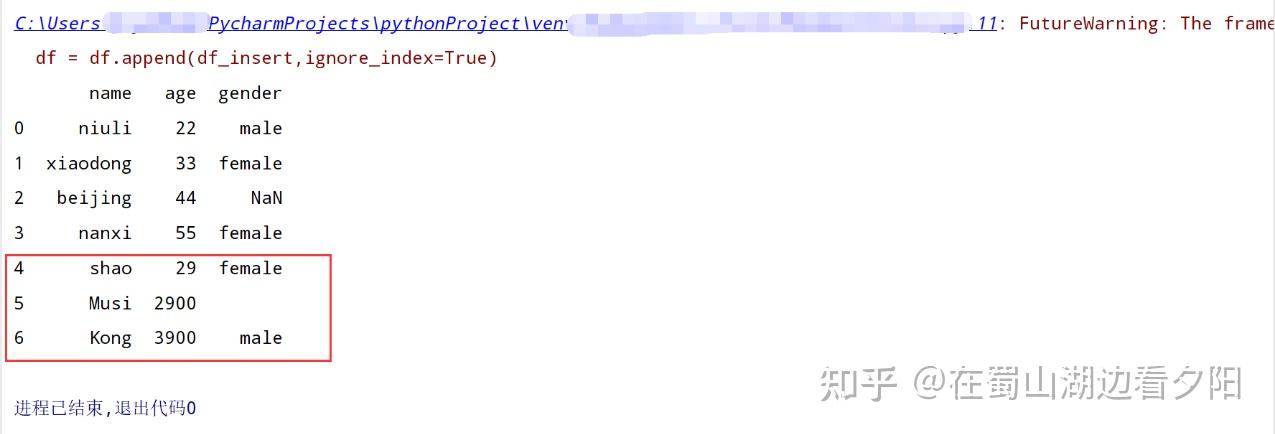
【注:pd.append()不止是可以增加单行,只要将数据编成相同columns的DataFrame数据,都可以合并的】
这里仅举一个list的例子。同时可以探索一下将list转化成DataFrame的N种方式~
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#df.append()
insert_data = [['shao',29,'female'],['Musi',2900,''],['Kong',3900,'male']]
#将列表数据转换成DataFrame数据结构。
df_insert = pd.DataFrame(insert_data)
# 设置相同columns。
df_insert.columns = ['name','age','gender']
# print(df_insert)
df = df.append(df_insert,ignore_index=True)
print(df)
1.3 pd.concat()
【注:推荐使用,这函数的用途非常广,这里篇幅会略长】
【注:这里不再讲如何将dict、list转化成DataFrame】
1.3.1 pd.concat()参数解读
pd.concat(
objs,#数据,如Series,DataFrame,list。
axis=0, #合并依据,是根据行标签,还是列标签。也可以理解为,增加行为0,增加列为1。
join='outer,inner', #两张表的连接方式,类似SQL中的JOIN。inner是两张表的交集。outer是两张表的并集。默认为outer。
join_axes=None, #弃用。用于inner join时保留哪张表的索引。
ignore_index=False, #是否忽略索引。
keys=None, #这个是用来标记数据来源的。比如合并两张表,那些表是一张表的数据,那些表是第二张表的数据,可以用keys=['t1','t2']
levels=None, #确定索引,默认为无。
names=None, #给合并后数据结构添加名字。用list形式。如names=['来源表','索引列']
verify_integrity=False, #
sort=None, #排序,布尔值:True、False,默认为无。True时会重新排序。False则出现警告,不重新排序。
copy=True,#
)
1.3.2增加一行
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#df.concat()
insert_data = [['shao',29,'female']]
#将列表数据转换成DataFrame数据结构。
df_insert = pd.DataFrame(insert_data)
# 设置相同columns。
df_insert.columns = ['name','age','gender']
# print(df_insert)
#将需要合并的数据放到list中。
df = pd.concat([df,df_insert],axis=0,ignore_index=True)
print(df)

1.3.3 增加多行
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#df.concat()
insert_data = [['shao',29,'female'],['Musi',2900,''],['Kong',3900,'male']]
#将列表数据转换成DataFrame数据结构。
df_insert = pd.DataFrame(insert_data)
# 设置相同columns。
df_insert.columns = ['name','age','gender']
# print(df_insert)
#将需要合并的数据放到list中。
df = pd.concat([df,df_insert],axis=0,ignore_index=True)
print(df)

1.3.3 合并两个sheet表
import pandas as pd
#读取第一张sheet中的数据
df_1 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
#读取第二张sheet中的数据
df_2 = pd.read_excel(r'C:\Users\XXXXX\Desktop\pandas练习文档.xlsx',sheet_name=2)
#将需要合并的数据放到list中。
df = pd.concat([df_1,df_2],axis=0,ignore_index=True)
print(df)

2、增加列数据
2.1 df['col_name']=values
直接赋值
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#增加一列
df['job'] = ['student','doctor','lawyer','teacher']
print(df)

2.2 df.loc[:,'new_col_name'] = values
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#增加一列,注意行数应于df的行数相同,否则会报错。
df.loc[:,'job'] = ['student','doctor','lawyer','teacher']
print(df)

2.3 df.insert()
2.3.1 参数详解
df.insert(
loc, #位置索引,必要字段。
column, #列标签名,必要字段。
value,#值,Series,list,str,float,int等。必要字段。
allow_duplicates = False#布尔值,用于检查是否存在具有相同名称的列。默认为False,不允许与已有的列名重复。
)
2.3.2 插入一列
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df.insert(loc=2,column='job',value=['student','doctor','lawyer','teacher'],allow_duplicates=False)
print(df)

2.4 pd.concat()
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#使用pd.concat()拼接,加一列空列,然后再赋值。这个方法不推荐。
df_new = pd.concat([df,pd.DataFrame(columns=['job'])],sort=False)
df_new['job'] = ['student','doctor','lawyer','teacher']
print(df_new)

2.5 df.reindex()
【注:思路与pd.concat()添加新列相似】
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#使用df.reindex()新建一列,并填充数据。
df = df.reindex(columns = ['name','age','gender','job'],fill_value=0)
df['job'] = ['student','doctor','lawyer','teacher']
print(df)

2.6 增加多列
【注:先利用pd.concat()、df.reindex(),增加空列再赋值】
方式1:
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#使用df.reindex()新建一列,并填充数据。
df = df.reindex(columns = ['name','age','gender','job','city'],fill_value=0)
df['job'] = ['student','doctor','lawyer','teacher']
df['city'] = ['chengdu','nanjing','xian','beijing']
print(df)

方式2:
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
#使用pd.concat()拼接,加一列空列,然后再赋值。这个方法不推荐。
df_new = pd.concat([df,pd.DataFrame(columns=['job','city'])],sort=False)
df_new['job'] = ['student','doctor','lawyer','teacher']
df['city'] = ['chengdu','nanjing','xian','beijing']
print(df_new)

3、合并数据
3.1 pd.concat()
3.1.1 行合并
在增加行数据中已有涉及,此处不再论述。
3.1.2 列合并
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df1 = pd.DataFrame({
'job':['student','doctor','lawyer','teacher'],
'city':['chengdu','nanjing','xian','beijing']
})
df = pd.concat([df,df1],axis=1)
print(df)

3.2 df.join()
3.2.1 df.join()参数详解
df.join(
other, #数据,df数据结构
on=None, #列名,默认使用索引连接。
how='left', #连接方式,默认使用左连接。{'left', 'right', 'outer', 'inner'}, default:'left'
lsuffix='', #左边df中重复列的后缀
rsuffix='', #右边df中重复列的后缀
sort=False
)
3.2.2 列合并
1)没有相同列的合并
import pandas as pd
#读取数据
df = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df1 = pd.DataFrame({
'job':['student','doctor','lawyer','teacher'],
'city':['chengdu','nanjing','xian','beijing']
})
df_new = df.join(df1)
print(df_new)

2)根据相同列合并
根据'name'列合并
import pandas as pd
#读取数据
df_0 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df1 = pd.DataFrame({
'name':['Ann','Lucy','nanxi','niuli'],
'job':['student','doctor','lawyer','teacher'],
'city':['chengdu','nanjing','xian','beijing']
})
#因为df.join()总是根据other索引匹配的,所以,要在连接前重置索引。具体重置索引内容会在【修改数据】篇介绍。
df_0 = df_0.set_index('name')
df1 = df1.set_index('name')
# print(df1)
df_new = df_0.join(df1,on='name',lsuffix='_0',rsuffix='_1')
print(df_new)

【注:其他连接方式不再举例,可自行操作】
可参考:pandas中DataFrame的连接操作:join - 简书
3.3pd.merge()
【注:这个与excel中的Vlookup,SQL中的表连接相似】
pd.merge()与pd.concat()最大的不同在于,pd.merge()不能进行数据的上下连接,只能进行两张表的左右连接。
3.3.1 pd.merge()参数详解
pd.merge(
left, right, #左表、右表
how='inner', #连接方式,默认内连接,即只会输出交集部分。{'left', 'right', 'outer', 'inner', 'corss'}
on=None, #设置关键字参数。哪一列作为主键列。
left_on=None, #针对没有相同列名的两张表,可以用left_on和right_on参数。
right_on=None, #针对没有相同列名的两张表,可以用left_on和right_on参数。
left_index=False, #默认为False,即不以索引作为主键。若以索引作为主键,设置为True。
right_index=False, #默认为False,即不以索引作为主键。若以索引作为主键,设置为True。
sort=False,
suffixes=('_x', '_y'), #后缀设置。
copy=True,
indicator=False, #对数据标记来源。
validate=None,
)
3.3.2 inner内连接
import pandas as pd
#读取数据
df_1 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df_3 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
# print(df_1,df_3,sep='\n\n')
#根据名字进行连接
df_new = pd.merge(df_3,df_1,left_on='name',right_on='name',suffixes=('_3','_1'))
print(df_new)

3.3.3 左联结
【注:以左边的表为主表】
import pandas as pd
#读取数据
df_1 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df_3 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
# print(df_1,df_3,sep='\n\n')
#根据名字进行连接
df_new = pd.merge(df_3,df_1,how='left',left_on='name',right_on='name',suffixes=('_3','_1'))
print(df_new)

3.3.4 右连接
【注:以右边的表为主表】
import pandas as pd
#读取数据
df_1 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df_3 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
# print(df_1,df_3,sep='\n\n')
#根据名字进行连接
df_new = pd.merge(df_3,df_1,how='right',left_on='name',right_on='name',suffixes=('_3','_1'))
print(df_new)

输出的id是float64类型的,为什么呢?
右边的表缺少的id,NaN填入,pandas中,在不指定数据类型的情况下,默认为是float,id为str,NaN默认为float合并之后,这一列的数据类型就变成了float的。所以一般情况下,不要采用这种方式. 3.3.5 外连接
import pandas as pd
#读取数据
df_1 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=1)
# print(df)
df_3 = pd.read_excel(r'C:\Users\XXXXXX\Desktop\pandas练习文档.xlsx',sheet_name=3)
# print(df_1,df_3,sep='\n\n')
#根据名字进行连接
df_new = pd.merge(df_3,df_1,how='outer',left_on='name',right_on='name',suffixes=('_3','_1'))
print(df_new)
 |
|



 发表于 2023-1-16 07:15:02
发表于 2023-1-16 07:15:02