|
|
上一篇我们大概已经讲了内核简单的处理数据的一些流程。那么接下来,我们要好好讲讲排版引擎这个东西了。
语系
首先在讲排版引擎之前,必须得先说下语系!这个目前可能大家都不太在意这件事儿。但是这个真的是排版引擎的基础。下面列一下,关于语系的分类,这是目前世界主流的语系分类
以下摘自Wiki
- 印欧语系(欧洲、西亚、中亚、南亚、东亚、北亚、美洲、大洋洲、南部非洲)
- 汉藏语系(东亚、南亚、东南亚、中亚)
- 尼日尔-刚果语系(撒哈拉以南非洲)
- 亚非语系(南欧、北非、东北非、西亚)
- 南岛语系(东亚、东南亚、马达加斯加、美拉尼西亚、密克罗尼西亚、波利尼西亚)
- 达罗毗荼语系(南亚)
- 突厥语系(东欧、西亚、南亚、中亚、北亚、东亚)
- 日本语系(东亚)
- 南亚语系(东南亚、东亚、南亚)
- 壮侗语系(东南亚、东亚)
- 朝鲜语系(东亚)
- 尼罗-撒哈拉语系(中部非洲、东非)
- 乌拉尔语系(北欧、东欧、北亚)
- 苗瑶语系(东亚、东南亚)
- 克丘亚语系(南美)
- 图皮语系(南美)
- 玛雅语系(中美)
- 蒙古语系(东欧、南亚、北亚、东亚)
- 南高加索语系(高加索地区)
- 跨新几内亚语系(美拉尼西亚)
- 犹他-阿兹特克语系(北美、中美)
- 西北高加索语系(高加索地区)
- 欧托-曼格语系(中美)
- 科依桑语系(西非、南部非洲)
- 帕马-恩永甘语系(澳大利亚)
- 东北高加索语系(高加索地区)
- 爱斯基摩-阿留申语系(北美)
- 奇布恰语系(中美、南美)
- 塞皮克-拉穆语系(美拉尼西亚)
- 通古斯语系(东亚、北亚)
- 博拉-维托托语系(南美)
- 阿尔吉克语系(北美)
- 易洛魁语系(北美)
- 楚科奇-堪察加语系(北亚)
- 纳-德内语系(北美)
- 萨利希语系(北美)
- 叶尼塞语系(北亚)
- 安达曼语系(安达曼群岛)
- 尤卡吉尔语系(北亚)
像汉语的话,就属于典型的汉藏语系(主要分布于 东亚、南亚、东南亚、中亚)
语言学家认定汉藏语系存在的标准,是该语系中的共享词汇。比如古汉语中“五”“吾”“鱼”的发音,和藏语、缅语这三个词的发音都非常相似,而三个词的语义并没有联系,而且都是语言里面非常基本的词汇,很难从其它语言借用,因此认定这几个词有共同来源的。 那么今天,作者规定,下面就得讲中文-即汉藏语系!
排版引擎的历史
WYSIWYG - What You See Is What You Get
即现代排版引擎都支持的所见即所得。不管是从远古时代的 HP Draw,到接下来的WordStar,这些实际上并没有达到WYSIWYG的真实场景。真正将这个口号实现的也就是大名鼎鼎的Apple了
1983年,《读者周刊》以 "所见即所得 "的口号为其Stickybear教育软件做广告,并附有Apple II图形的照片[10],但1970年代和1980年代初的家用电脑缺乏显示所见即所得文件所必需的复杂图形功能,这意味着这种应用通常局限于用途有限的高端工作站,而这些工作站对于普通大众来说过于昂贵。随着技术进步让更便宜的位图显示器得以生产,所见即所得软件开始出现在更流行的计算机中,包括 1983 年发布的用于Apple Lisa的LisaWrite和 1984 年发布的用于Apple Macintosh的MacWrite 。 那么接下来就是Apple跟MicroSoft的世纪官司了。
- Macintosh 桌面
Windows 2.0
对于现代富文本编辑器来说,这个概念可以说是检测一个编辑器是否成熟的标准了。历史说的有点多,下面继续将排版引擎。
中文排版
首先不得不说,如果不算字符 & 字母的话,中文的排版引擎是最简单的,为啥这样说呢,因为中文都是等宽字体,在计算上是非常简单的。那么如果我们要实现一个最简单的排版引擎的话。首先得需要一个设备大小,让我们排版。像WPS的话,默认新建就是常规的A4纸大小了。
OK,那么纸张大小有了,你总不能直接在左上角(0, 0)处直接绘制吧,所以才会有了页边距的概念
那么一个默认的A4创建后页边距是。
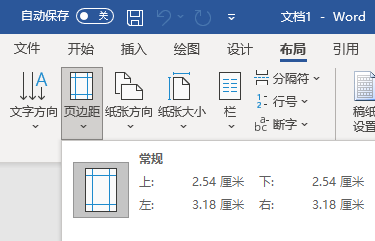
那么我们排版的核心排版区域就有了

实际上,单纯的中文排版是比较简单的。最简单图示大概就是这样 - 纯手工绘制,见谅
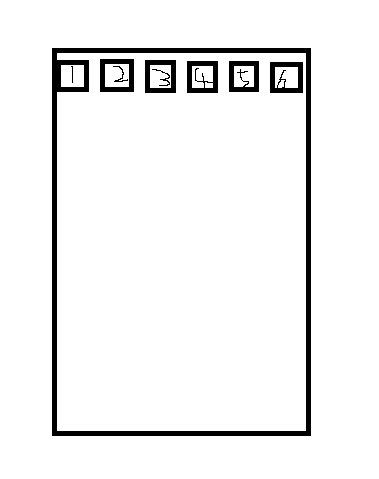
如图所示,当当前的页面区域拍不下下一个字符的时候,下一个数字7,就得继续乖乖的去下一行继续去排布了。那么简单的流程就有了。
- 获取当前可排版页面的宽度。
- 获取每个字符的绘制宽度,属性(加粗,缩放,倾斜巴拉巴拉巴拉),计算出每个字符的宽度。
- 每次排都要计算已经排好的元素总长度是不是超过当前行宽。(正常的从左到右,横排文字)
- 正常的换行。继续下一个计算
当然,这是最最最最最最最最简单的一个模型了。真实的排版引擎肯定不是这么简单的。更要考虑各种各种场景。除了常规的字体本身自带的属性(比如宽,高,字距调整-即Kerning),还有比如缩放,加宽,倾斜等各种附加属性。
下面贴一个FreeType中关于字体的关键图
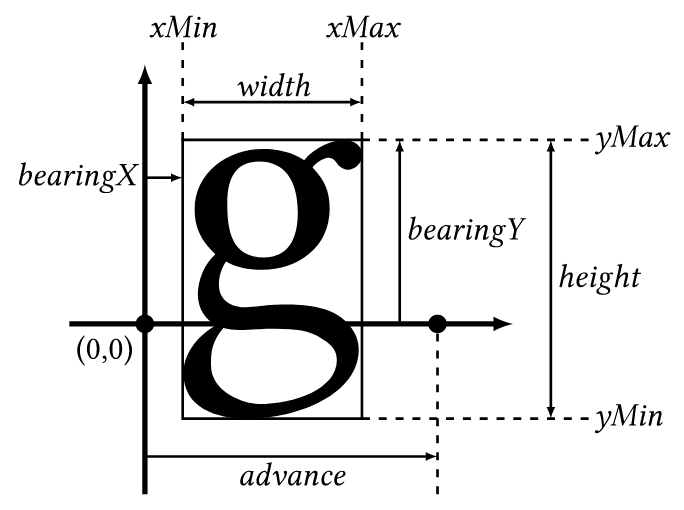
听起来已经够复杂了吧,实际上WPS支持更多的属性设置
随便贴个图。
字符间距
段落基础属性设置
随便举个换行跟分页
里面随便一个选项的控制,都会影响最终一行行排版的效果。甚至为了好看,所以才会有这么多选项。
开源的排版引擎 - HarfBuzz
HarfBuzz是一个非常优秀的开源的排版引擎,目前最新的HarffBuzz版本前几天又刚刚才更新。HarfBuzz最新的版本应该叫HarfBuzz-NG,以便于跟老的HarfBuzz区分开。
5.3.0 Latest
- Don’t add glyphs from dropped MATH or COLR tables to the subset glyphs. (Khaled Hosny)
- Map rlig to appropriate AAT feature selectors. (Jonathan Kew)
- Update USE data files to latest version. (David Corbett)
- Check CBDT extents first before outline tables, to help with fonts that also include an empty glyf table. (Khaled Hosny)
- More work towards variable font instancing in the subsetter. (Qunxin Liu)
- Subsetter repacker improvements. (Garret Rieger)
New API:
- hb_ot_layout_lookup_get_optical_bound()
- hb_face_builder_sort_tables()
目前很多优秀的第三方库都使用HarffBuzz来作为自己的排版引擎以便于支持富文本编辑。就光多语言支持这一项,就足够让各个第三方库青睐了。感恩开源社区。
Qt
就拿我比较熟悉的Qt来说吧。Qt4版本内部应该使用的是HarfBuzz老的分支,到了Qt5,已经升级到最新的HarfBuzz-NG了。目前Qt提供文本级别的控件 & API,内部都是使用的HarfBuzz来进行的排版。所以,Qt的文本编辑器也是支持多语系的。
这里可以举个栗子了 - Qt,开源,你们都有代码的
栗子 - QTextLayout
我们这里用Qt的QTextLayout来举个例子吧。先上Qt的Demo
QFontMetrics fontMetrics(font());
int leading = fontMetrics.leading();
qreal height = 0;
textLayout.setText("wdsadsadsa");
textLayout.setCacheEnabled(true);
textLayout.beginLayout();
while (1) {
QTextLine line = textLayout.createLine();
if (!line.isValid())
break;
line.setLineWidth(10);
height += leading;
line.setPosition(QPointF(0, height));
height += line.height();
}
textLayout.endLayout();
然后随便找个控件,写上Paint函数
QPainter painter(this);
textLayout.draw(&painter, QPoint(0, 0));跟踪到Qt的源码中,你会发现Qt源码是这样调用的
void QTextEngine::shapeText(int item) const
{
Q_ASSERT(item < layoutData->items.size());
QScriptItem &si = layoutData->items[item];
xxxxxxxxxxxxxxxxxxxxxxxx
for (int i = 0; i < si.num_glyphs; ++i)
si.width += glyphs.advances_x * !glyphs.attributes.dontPrint;
xxxxxxxxxxxxxxxxxxxxxxxx
}
仔细看这段代码,你会发现字符也是一个个的去便利当前Glyph的 advances_x, 那么advance是啥呢,
这时候再重复贴下这个图
这时候你就知道了,这时候Qt正在计算一行的排版。那么代码中的 QScriptItem 最终干啥了。看接下来的代码。下面太长,你们可以忽略,有兴趣的可以简单读一下,小200行代码。
```cpp
int QTextEngine::shapeTextWithHarfbuzzNG(const QScriptItem &si,
const ushort *string,
int itemLength,
QFontEngine *fontEngine,
const QVector<uint> &itemBoundaries,
bool kerningEnabled,
bool hasLetterSpacing) const
{
uint glyphs_shaped = 0;
hb_buffer_t *buffer = hb_buffer_create();
hb_buffer_set_unicode_funcs(buffer, hb_qt_get_unicode_funcs());
hb_buffer_pre_allocate(buffer, itemLength);
if (Q_UNLIKELY(!hb_buffer_allocation_successful(buffer))) {
hb_buffer_destroy(buffer);
return 0;
}
hb_segment_properties_t props = HB_SEGMENT_PROPERTIES_DEFAULT;
props.direction = si.analysis.bidiLevel % 2 ? HB_DIRECTION_RTL : HB_DIRECTION_LTR;
QCharScript script = qt_UnicodeScriptToCharScript((QUnicodeTables::Script)si.analysis.script);
props.script = hb_qt_script_to_script(script);
// ### props.language = hb_language_get_default_for_script(props.script);
for (int k = 0; k < itemBoundaries.size(); k += 3) {
const uint item_pos = itemBoundaries[k];
const uint item_length = (k + 4 < itemBoundaries.size() ? itemBoundaries[k + 3] : itemLength) - item_pos;
const uint engineIdx = itemBoundaries[k + 2];
QFontEngine *actualFontEngine = fontEngine->type() != QFontEngine::Multi ? fontEngine
: static_cast<QFontEngineMulti *>(fontEngine)->engine(engineIdx);
// prepare buffer
hb_buffer_clear_contents(buffer);
hb_buffer_add_utf16(buffer, reinterpret_cast<const uint16_t *>(string) + item_pos, item_length, 0, item_length);
hb_buffer_set_segment_properties(buffer, &props);
hb_buffer_guess_segment_properties(buffer);
uint buffer_flags = HB_BUFFER_FLAG_DEFAULT;
// Symbol encoding used to encode various crap in the 32..255 character code range,
// and thus might override U+00AD [SHY]; avoid hiding default ignorables
if (Q_UNLIKELY(actualFontEngine->symbol))
buffer_flags |= HB_BUFFER_FLAG_PRESERVE_DEFAULT_IGNORABLES;
hb_buffer_set_flags(buffer, hb_buffer_flags_t(buffer_flags));
// shape
{
hb_font_t *hb_font = hb_qt_font_get_for_engine(actualFontEngine);
Q_ASSERT(hb_font);
hb_qt_font_set_use_design_metrics(hb_font, option.useDesignMetrics() ? uint(QTextEngine::DesignMetrics) : 0); // ###
// Ligatures are incompatible with custom letter spacing, so when a letter spacing is set,
// we disable them for writing systems where they are purely cosmetic.
bool scriptRequiresOpenType = ((script >= Script_Syriac && script <= Script_Sinhala)
|| script == Script_Khmer || script == Script_Nko);
bool dontLigate = hasLetterSpacing && !scriptRequiresOpenType;
const hb_feature_t features[5] = {
{ HB_TAG(&#39;k&#39;,&#39;e&#39;,&#39;r&#39;,&#39;n&#39;), !!kerningEnabled, 0, uint(-1) },
{ HB_TAG(&#39;l&#39;,&#39;i&#39;,&#39;g&#39;,&#39;a&#39;), !dontLigate, 0, uint(-1) },
{ HB_TAG(&#39;c&#39;,&#39;l&#39;,&#39;i&#39;,&#39;g&#39;), !dontLigate, 0, uint(-1) },
{ HB_TAG(&#39;d&#39;,&#39;l&#39;,&#39;i&#39;,&#39;g&#39;), !dontLigate, 0, uint(-1) },
{ HB_TAG(&#39;h&#39;,&#39;l&#39;,&#39;i&#39;,&#39;g&#39;), !dontLigate, 0, uint(-1) } };
const int num_features = dontLigate ? 5 : 1;
const char *const *shaper_list = Q_NULLPTR;
bool shapedOk = hb_shape_full(hb_font, buffer, features, num_features, shaper_list);
if (Q_UNLIKELY(!shapedOk)) {
hb_buffer_destroy(buffer);
return 0;
}
if (Q_UNLIKELY(HB_DIRECTION_IS_BACKWARD(props.direction)))
hb_buffer_reverse(buffer);
}
const uint num_glyphs = hb_buffer_get_length(buffer);
// ensure we have enough space for shaped glyphs and metrics
if (Q_UNLIKELY(num_glyphs == 0 || !ensureSpace(glyphs_shaped + num_glyphs))) {
hb_buffer_destroy(buffer);
return 0;
}
// fetch the shaped glyphs and metrics
QGlyphLayout g = availableGlyphs(&si).mid(glyphs_shaped, num_glyphs);
ushort *log_clusters = logClusters(&si) + item_pos;
hb_glyph_info_t *infos = hb_buffer_get_glyph_infos(buffer, 0);
hb_glyph_position_t *positions = hb_buffer_get_glyph_positions(buffer, 0);
uint str_pos = 0;
uint last_cluster = ~0u;
uint last_glyph_pos = glyphs_shaped;
for (uint i = 0; i < num_glyphs; ++i, ++infos, ++positions) {
g.glyphs = infos->codepoint;
g.advances_x = QFixed::fromFixed(positions->x_advance);
g.offsets.x = QFixed::fromFixed(positions->x_offset);
g.offsets.y = QFixed::fromFixed(positions->y_offset);
uint cluster = infos->cluster;
if (Q_LIKELY(last_cluster != cluster)) {
g.attributes.clusterStart = true;
// fix up clusters so that the cluster indices will be monotonic
// and thus we never return out-of-order indices
while (last_cluster++ < cluster && str_pos < item_length)
log_clusters[str_pos++] = last_glyph_pos;
last_glyph_pos = i + glyphs_shaped;
last_cluster = cluster;
// hide characters that should normally be invisible
switch (string[item_pos + str_pos]) {
case QChar::LineFeed:
case 0x000c: // FormFeed
case QChar::CarriageReturn:
case QChar::LineSeparator:
case QChar::ParagraphSeparator:
g.attributes.dontPrint = true;
break;
case QChar::SoftHyphen:
if (!actualFontEngine->symbol) {
// U+00AD [SOFT HYPHEN] is a default ignorable codepoint,
// so we replace its glyph and metrics with ones for
// U+002D [HYPHEN-MINUS] and make it visible if it appears at line-break
g.glyphs = actualFontEngine->glyphIndex(&#39;-&#39;);
if (Q_LIKELY(g.glyphs != 0)) {
QGlyphLayout tmp = g.mid(i, 1);
actualFontEngine->recalcAdvances(&tmp, 0);
}
g.attributes.dontPrint = true;
}
break;
default:
break;
}
}
}
while (str_pos < item_length)
log_clusters[str_pos++] = last_glyph_pos;
if (Q_UNLIKELY(engineIdx != 0)) {
for (quint32 i = 0; i < num_glyphs; ++i)
g.glyphs |= (engineIdx << 24);
}
#ifdef Q_OS_DARWIN
if (actualFontEngine->type() == QFontEngine::Mac) {
if (actualFontEngine->fontDef.stretch != 100) {
QFixed stretch = QFixed(int(actualFontEngine->fontDef.stretch)) / QFixed(100);
for (uint i = 0; i < num_glyphs; ++i)
g.advances *= stretch;
}
}
#endif
if (actualFontEngine->type() != QFontEngine::Win || (actualFontEngine->fontDef.styleStrategy & QFont::ForceIntegerMetrics)) {
for (uint i = 0; i < num_glyphs; ++i)
g.advances_x = g.advances_x.round();
}
glyphs_shaped += num_glyphs;
}
hb_buffer_destroy(buffer);
return glyphs_shaped;
}
```
反正都贴上吧,估计你们也会懒得看的。具体就是调用HarfBuzzNG的代码来进行排版,然后再进行绘制。Qt也可以当作一个富文本编辑器的一个参考吧。毕竟开源的,可以随意学习,而且还简单。我觉得对前端富文本编辑器的开发来说是一个很好的例子参考(虽说是c++的代码
字体
实际上字体对于一个排版引擎来讲是非常重要的。目前不同系统解析字体的库是不一样的。在Windows平台,当然乖乖的使用Windows API相关的函数了。
Others的平台,基本上大家都是选择的开源库 - FreeType。
但是关键问题是,FreeType的渲染引擎对中文相对来说是非常不友好的。更别提一些第三方库对于FreeType的封装了。
比如在Linux平台,对于一些中文字形,一些第三方库的加粗 & 渲染效果,对于Windows平台,甚至都是不一样的。你说他是Bug吧,他确实跟Windows有一些差距。
那么,作为一个开发,为了保证软件的表现一致,那就只能自己来动手改字体相关的代码了。
甚至我还写了几个专利,这是题外话了。
具体的字体相关的解析绘制,我还是放到渲染篇吧。 |
|



 发表于 2022-12-17 20:15:14
发表于 2022-12-17 20:15:14